Principal Investigators
| Lixia Zhang |
| Deborah Estrin |
| Jeffrey Burke |
| Van Jacobson |
| James D. Thornton |
| Ersin Uzun |
| Beichuan Zhang |
| Gene Tsudik |
| kc claffy |
| Dmitri Krioukov |
| Dan Massey |
| Christos Papadopoulos |
| Tarek Abdelzaher |
| Lan Wang |
| Patrick Crowley |
| Edmund Yeh |
During the first year of our NSF-funded Named-Data Networking project, we mainly focused on understanding how appropriate naming can facilitate application development and network service delivery. We obtain that understanding through development and experimental deployment of pilot applications. This investigation enables us to identify a set of general principles and guidelines for naming in NDN networks, and to translate these into naming conventions implemented in system libraries. Library implementation operationalizes what we have learned in a form that supports consistent reuse, to simplify future application development and accelerate progress.
The opaqueness of names to the network and their significance of application concerns enables the design and development of the NDN architecture to proceed in parallel with our research into name structure, name discovery and namespace navigation, all studied in the context of application development. Thus we began the project, as planned, with significant investigation of application development, in parallel with our work on data forwarding strategies and the development of an overlay testbed with routing. These three pieces together have given us an operational NDN environment where we can ask and answer various NDN design questions. At the same time we have also advanced on other fronts including forwarding performance, advanced routing opportunities, security and privacy, and the fundamental theory for this new type of network with in-network memory.
We have successfully achieved all our major milestones for the first year of this project. Our early successes have provided preliminary evidence that we may able to invent a new and improved waist of the Internet’s hourglass architecture. The first section of this report lists research accomplishments for each area of the project: applications; routing; forwarding strategy; security and privacy; network management and monitoring; evaluation and assessment; and fundamental theory for NDN. The second section provides more detail on each of these areas, including objectives, technical approach, activities and findings for this year, and recent publications. The third section focuses on the educational component of our mission, including teaching students how to rigorously evaluate the systemic and computational impacts of architecture design choices.
Section 1: Research Accomplishments
1.1 Progress: Year 1
- Applications (Section 2.1)
- Development of a basic conferencing application
- Prototype of an instrumented environments application
- Prototype of a set of participatory sensing applications
- Routing (Section 2.2)
- Designed and implemented a protocol for bootstrapping edge-node connectivity by allowing an NDN node to discover NDN routers. The new named-data way of thinking contrasts with existing bootstrapping practice in fundamental ways.
- Designed and performed feasibility assessment of an extension of OSPF for NDN that we call “OSPF-N”, using new types of Opaque Link State Advertisements (LSA) to carry NDN routing information.
- Designed a routing security model to establish trust with interior gateway protocols (extensible to exterior gateway protocols). This model provides effective protection against malicious outsiders and minimizes potential of malicious insiders to cause damage. The approach extends established operational practice and utilizes topological adjacency relationships to establish cryptographic relations.
- Obtained analytic expression needed to estimate number of common neighbors between nodes for routing on hypberbolic metric space and clean formulation of growing network model, validated against history of growing Internet confirming model prediction.
- Forwarding Strategy (Section 2.3)
- Implemented the basic NDN forwarding mechanism in QualNet simulator.
- Initial design of a couple of simple forwarding strategies.
- Simulation study to compare IP and NDN in terms of packet delivery resilience against various network problems.
- Proposed Interest-NACK and started evaluating this mechanism.
- Scalable Forwarding (Section 2.4)
- Established a performance baseline of the NDN reference implementation, measured experimentally using Open Network Lab (ONL) with 10s of routers.
- Deployed NDN reference implementation on 5 Supercharged PlanetLab Nodes within the GENI infrastructure.
- Security and Privacy (Section 2.5)
- Analysis of privacy in NDN. Analysis of TOR over NDN indicated that it is as good or better than IP at protecting user privacy. Implementation of anonymizing proxies framework is completed.
- Initial design for supporting encrypted names at the architectural level.
- Design and first implementation of signed Interests and models of bootstrapping trust/security in NDN applications.
- Survey and empirical evaluation of efficient signature schemes for NDN.
- Design of a routing security model in collaboration with the routing group.
- Network Management (Section 2.6)
- Identified policy knob options for NDN network operators.
- Developed a base Network Operations Center (NOC) design
- Evaluation and Experimental Infrastructure (Chapter 2.7)
- Established basic connectivity between project sites.
- Conducted Network Operations Center (NOC) experiments to inform the design of an effective management system.
- Developed a node naming convention that spans network management and other functions such as routing.
- Developed an initial NDN MIB and Java-based management agent.
- Theory (Chapter 2.8)
- Established the performance metric of total consumed bit rate to measure network capacity of the NDN architecture.
- Developed joint forwarding and caching algorithms which are driven by dynamic measures of both the current and future demand for data packets. These dynamic algorithms are designed to maximize the total consumed bit rate in the network.
- Developed forwarding and caching algorithms which explicitly model bidirectional traffic (interest packets to data source, and data packets back to the interest source), and which explicitly model the collapsing and suppression of interest packets requesting the same data type.
- Undertook both experimental and theoretical verification of the optimality of the proposed forwarding and caching algorithms.
- Education (Chapter 3)
- Incorporated NDN architecture into graduate teaching and research
- Developed NDN project education website, http://named-data.net/education.html
- Developed methodologies of teaching networking architectures through case studies.
Section 2: Architecture Research
The NDN design introduced in the Architecture Overview (Chapter ) represents a novel architectural blueprint with both unique opportunities and many challenges. This chapter presents a detailed description of the activities and findings in each of the project’s research areas, together with our findings so far and the milestone we set forth for the second year of the project.
2.1 Applications
|
2.1.1 Summary of Objectives
The NDN application research: (1) drives architecture development based on a broad vision for future applications; (2) drives and tests the prototype implementations of the architecture using applications in participatory sensing, instrumented environments, and media distribution; (3) demonstrates performance and functional advantages of NDN in key areas; and (4) shows how NDN’s embedding of application names in the routing system promotes efficient authoring of sophisticated distributed applications, reducing complexity and thus opportunities for error, as well as time and expense of design and deployment.
2.1.2 Technical Approach
Through the application development process and interaction with the other groups within the NDN project, especially security and routing, the application group provides feedback on the architecture and its initial reference implementation: features, performance, and interfaces. Our intention is to validate the design of the architecture through development and testing of specific applications to run over NDN.
Prototype applications are being developed using the CCNx software router codebase from PARC. Applications are using the C API, which provides low-level (socket-like) functionality and the Java API, which provides higher-level abstractions based on initial applications developed at PARC. Our first year of experience confirms that the approach of developing pilot applications to feedback architecture design is indeed fruitful, as described in the sections below.
Participatory sensing
A key area of application exploration is participatory sensing using mobile devices. The deployment of these new applications requires mobility support in the NDN architecture, as well as authentication through signatures and confidentiality via encryption. The basic operation of NDN, i.e.a consumer expresses interest for communication and data flows back following the state set up by the Interest packet, can be directly used to provide support for moving receivers. For moving senders, on the other hand, the mobile’s Interest packet will inform the receiving end to send Interest towards the mobile to retrieve the data. The mechanisms by which a mobile publisher offers data as it moves from AS to AS is an active area of research motivated by this and other applications.
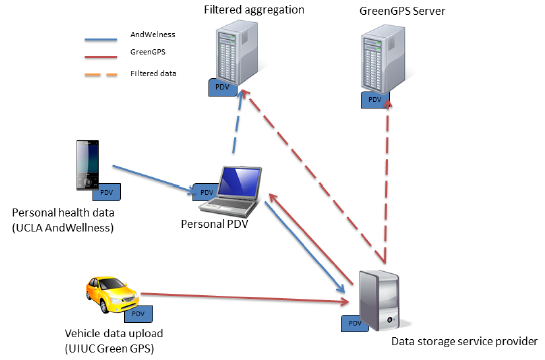
Within this application area, UCLA is first extending the host-centric “personal data vault” concept developed at UCLA and USC to create a geographically distributedpersonal data cloud (PDC). The PDC aims to provide local APIs to NDN-based filtered replication of data among a distributed set of devices and repositories, often starting with sensor data collected by mobile phones. Its high-level objective is to protect an individual’s data, supported by contractual or statutory legal protections against unauthorized use, similar to financial data, telecom conversations, and other privileged communications. Creating the PDC requires the implementation of a distributed database on NDN, providing a widely applicable test case that leverages the architecture’s features and supports content distribution systems implemented for the media-sensing application.
The PDC also informs NDN the requirements for data discovery, caching, and diverse models for trusted communication among mobile users, repositories, and applications, including: (1) disruption tolerant upload from sensors to the data store; (2) internal communication between nodes of the PDC; (3) filtered data sharing with authorized third-party applications providing personal services to the individual; and (4) filtered, often anonymous data sharing to aggregators.
In other participatory sensing work, UIUC is developing applications that explore mobility, monitoring, control, and data fusion. For example, to further test NDN in mobile environments, a testbed of 100 vehicles is being constructed using cars belonging to the UIUC Facilities and Services fleet. The car fleet will run an NDN- and PDC-based version of the GreenGPS software, currently under development. This navigation application interfaces with the vehicle’s engine to enable users to better understand performance with the goal of finding the most fuel-efficient routes, customized to the vehicle, to any given destination. GreenGPS was recently featured in the media as a new fuel saving navigation system from University of Illinois (see http://www.csl.illinois.edu/news/green-gps-news for a partial list).
Other UIUC applications that are being ported to NDN include environmental monitoring (video over NDN), control (of a green computing 160-core testbed that experiments with energy management in machine rooms), and data fusion over disruption-tolerant networks. The PhotoNet project is a “similarity-aware picture delivery service” for situational awareness, which aims to prioritize transmission of images over a mobile network for emergency response. Its goal is to prioritize the transmission of images that provides new information (i.e., similar looking images from the same location are low priority). PhotoNet provides an opportunity to explore the prioritized synchronization of media collections over NDN, also in a disruption tolerant networking context.
Instrumented environments
Practical public deployment of applications on heterogeneous, experiential cyber-physical systems has been limited by the host- and connection-based approach of the current Internet architecture, with its finite addressing schemes and security management difficulties, that impose major authoring challenges requiring substantial development resources. NDN’s intrinsic support for naming data, broadcast, caching, and fine-grained authentication provides obvious advantages to application developers.
We are creating NDN interfaces for representative, IP-enabled SCADA, sensing, and multimedia subsystems, and connecting them to the testbed NDN network to explore security, performance, and addressing features enabled by the architecture. Exploration of this area expands on UCLA’s experience in building interactive spaces of the kinds found in museums, theme parks, live performances, and physical simulation spaces. It is also informed by ongoing conversations with manufacturers such as Philips, Crestron, and Siemens about future aspirations for control networks and their practical deployment concerns and requirements.
UCLA has begun by building a lighting control application (including configuration, remote control, and device interface comments) for architectural and theatrical contexts, focusing on approaches that reduce the configuration complexity and brittleness inherent in the existing TCP/IP networked lighting control. Simultaneously, we are doing background research on more general building management systems, with plans to expand this application further over the next two years.
Work on this application has helped to prioritize directions for NDN architecture research including, for example: (1) application library support for name prefix publishing; the effective use of multiple namespaces, and other naming challenges; (2) the mDNS-style discovery of names by embedded devices; (3) support for distributed, synchronized state management that leverages the properties of NDN; and (4) effective key management and distribution for control packet authentication.
Media Distribution
NDN’s caching and name-based protocol has inherent advantages for media streaming, especially in improving the bandwidth efficiency of content distribution. We are leveraging PARC’s recent experience implementing Voice-Over-CCN to create a bi-directional secure high definition (HD) video and audio streaming service that uses named data packets, leverages content caching to provide multicast as well as point-to-point media distribution, offers multiple quality levels through the use of different name suffixes, and supports key management and time synchronization.
The first step in this area has been to develop at UCLA and PARC an Audio Conferencing Tool based on a pre-existing conference platform (Mumble/Murmur) adapted to NDN. Following this, the team will implement synchronized one-to-many video streaming using PARC’s plug-in for the popular VLC utility as a starting point. The implementation of these services on top of NDN is providing experience in the basic communication functions provided by NDN, the adaptation of client-server approaches to more distributed models that leverage NDN, and driving the security research by providing an opportunity to study application-specific trust models. Once ready, the tools will also be used for research coordination across different campuses.
Participatory Sensing Applications
We have completed an initial instance of the “Personal Data Cloud” for participatory sensing, including both a server-side implementation using the CCNx Java libraries and an Android implementation for mobile phones. The first design objective was to provide secure, distributed storage for participatory sensing, enabling users to set up filtered data streams that limit personal data available for remote applications. Initial work used an existing IP-based application for health monitoring from the Center for Embedded Networked Sensing, and replaced its data storage and networking with the PDC (and NDN). The PDC supports one-to-one and one-to-many streaming, the latter leveraging NDN in-network content caches. We have developed and implemented a naming, encryption, and authentication strategy, which along with the Instrumented Environment application, has helped to drive a requirements dialogue with the security team. By Fall 2011, we hope to integrate the PDC with a complete participatory sensing platform being developed at CENS, to drive additional traffic over the testbed.
Through the PDC, we are starting to explore naming, trust and authentication for applications which have a range of identity requirements, from real identity strongly coupled with a single signing key, to ephemeral or unlinked keys for per-application pseudonyms. This and the other applications have broadened our perspective on what should be the “default” implementations for keys and signatures. Concern with information leakage in this application has helped to prompt the security team to start developing generalized approaches for name and content encryption.
UIUC has completed initial prototypes in three areas: the control of energy parameters in the Green Computing (Cluster) Testbed using Interest packets as RPC calls; transfer of media captured by remote nodes using the CCNx library commands; end-to-end connectivity in the GreenGPS application; design and initial work on the PhotoNet application. Previous work on VoCCN at PARC inspired the integration of NDN with the pre-existing cluster as an “information tunnel” between clients and the cluster. Next, each will be scaled up and performance tested.
Conferencing Application
We have completed an initial prototype of an audio conferencing tool, ACT, using the CCNx C APIs. Developing ACT has helped to provide further understanding of application data naming and its relationship to routing scalability and trust models. After an initial binary is released in the next month, we expect it to serve as a useful tool for NDN collaborations and generate “real-world” traffic on the NDN testbed.
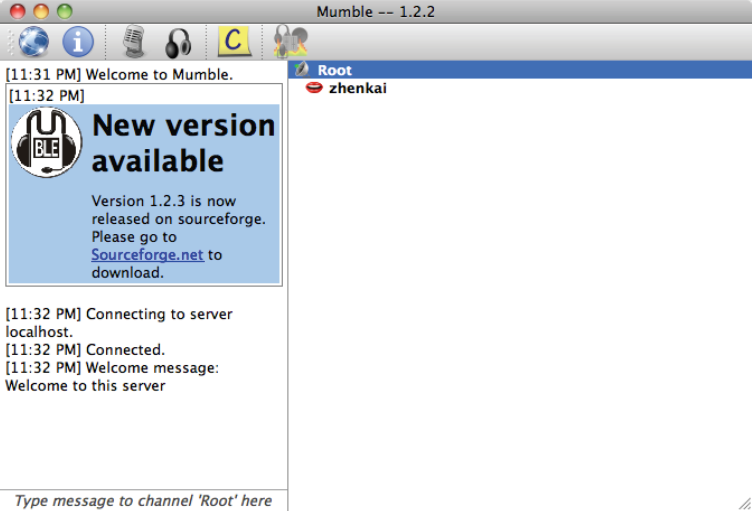
To focus our effort on NDN-specific design issues, ACT adopted a client-server-based open source audio application package called Mumble. This has also enabled us to learn more about how to migrate existing client-server applications to NDN. We keep the client code intact (see Figure 2.2) and run a modified murmurd, the server part of Mumble, on the same node with each client. The modified murmurd communicates with the client using the standard IP protocol stack and exchanges data with other murmurds over NDN for speaker discovery and voice data distribution. Conference and participant discovery was implemented using NDN via a new protocol, which enumerates names via “discovery” interests with exclusion filters. We have a simple user-interface for interacting with conferences (Figure 2.3).Assuming the existence of basic NDN trust management, per-packet signature verification and media encryption for security and privacy have also been implemented.
There is a significant learning and discovery process involved in creating new applications for such a nascent architecture as NDN, but we plan to move this tool into regular use over the next few months. Adapting an existing package enabled us to focus our research effort on NDN-specific design issues, and avoid non-NDN related, and often very challenging, issues such as user interface design and platform compatibility. We are currently working towards generalizing this approach for moving other existing client-server applications onto the NDN transport.
Binaries of the conferencing tool will be released in Summer 2011, to drive traffic over the testbed. After debugging and supporting ACT’s deployment, the next step will be to port XMPP messaging (e.g., Jabber) support to NDN. This will enable a broader range of communication tools to be used over NDN, requiring a more detailed namespace design and further investigation of group discovery and security. Simultaneously, in Fall 2011, we will begin development of a synchronized media streaming tool based on the well-known VLC codebase: this will test bandwidth efficiency and caching performance, as well as requiring us to develop an approach for efficient application-level time synchronization over NDN.
Instrumented Environments Application
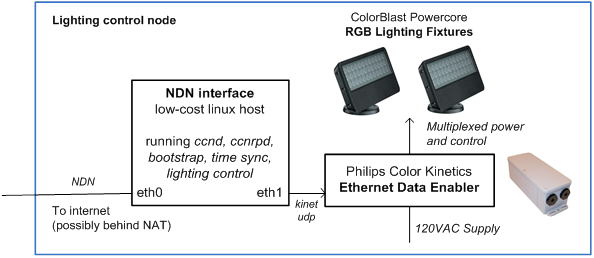
We have completed a working end-to-end application instance for architectural lighting control, consisting of a daemon running on an embedded Linux controller (along with a straightforward port of the CCNx routing daemon; see Figure 2.4) and a remote control process running on a workstation. The daemon controls ethernet-based light fixtures on one interface according to RPC calls embedded in the Interest packets received on other interfaces. We have also developed an application strategy for naming and name assignment, trust, and device configuration over NDN, as well as a prototype implementation of signed Interests that we hope to generalize for similar applications. The lighting application is deployed in a UCLA television studio, controlling ten multi-element LED fixtures and a variety of incandescent fixtures. This is a partial completion of the goal of a prototype instrumented environments application, as we would like to also integrate device discovery by enumeration of devices in the lighting namespace.
Efforts in instrumented environment applications provided us not only another rich lesson on the name space design choices for different applications, but they also exposed special requirements from instrumented environments, where large number of small devices must be first securely configured. This differs in fundamental ways from the end host communication model one normally has in mind, where each host is a fully functioning entity when it expresses interests in receiving various data. The basic NDN functions have been adjusted to meet these special requirements, i.e. the addition of signed Interests in order to securely control and start initial configuration of environmental devices such as light fixtures. We see this having application to other networked control systems as well. Resource constraints and high packet rates per device have also motivated the exploration of alternatives to signatures (e.g., HMAC-based authentication) jointly by the security and applications groups. Next, we will deploy the lighting control application for continuous use in a UCLA Television Studio, and build out key management and authentication fully for the system.
The UIUC Green Computing (Cluster) Testbed, mentioned above, also explores the Instrumented Environments space, offering monitoring and control of energy-related parameters of a machine cluster used by 5 research groups, 28 accounts, 2 departments. It is based on the CCNx Java codebase.
Note that this application and the participatory sensing application involve work on mobile and embedded platforms, respectively, and this has helped to direct the applications team’s attention to issues related to mobility, resource constraints, and device bootstrapping. We feel this will continue to broaden our perspective on how NDN can be used in a variety of hardware contexts and provide feedback into architecture design and testbed choices.
Architectural Findings from Application Development
Application development has generated questions and design patterns that inform further development of the NDN architecture. These findings were reported at the project retreat and the NDN core group is looking into them. The application team also interacts regularly around each application with both the project’s security and architectural researchers through coordination calls and in-person meetings.
- Long-lived Interests: Several of the applications wish to issue Interests that have long expiration times relative to the current PIT timeouts. The architecture team has begun to outline the possibility of long-lived interests that would better support them. We expect to use this new functionality in several of the applications.
- Authenticated Interests: In our control applications, such as lighting control being developed at UCLA and compute cluster management at UIUC, Interest packets are used to perform the equivalent of RPC calls. The semantics remain consistent with NDN: the Interest requests data confirming the outcome of a side effect. This single round-trip is simple and low-latency. However, these commands must be authenticated, which has led to discussions of signed interests. Early libraries by the application and security teams have been implemented to demonstrate this new feature and suggest it could be supported by the architecture, along with additional mechanisms to prevent replay attacks and support name encryption where necessary. Additionally, the use of HMACs in place of public key signatures is also being explored.
- Name Enumeration: The lighting control and other applications require more robust and efficient mechanisms for name enumeration than currently exist in the architecture. Both the applications and architecture teams are now working on mechanisms to efficiently request all of the child names currently published under a given prefix. Based on feedback from the application group and others, the Bloom filter based exclusion method will be deprecated from Interests, and other, more efficient mechanisms than the remaining suffix list-based exclusion are desired.
- Collection Synchronization: The Personal Data Cloud and PhotoNet applications have brought into relief the need for an efficient mechanism for synchronizing collections of data efficiently and without relying on stored state. The architecture team is exploring new mechanisms based on efficient set reconciliation, which will then be integrated into the applications.
- Local and Remote Architectural Consistency: The desire of several application developers is to use NDN primitives consistently with both local and remote scope (e.g., raising issues of whether or not content can be “forced” into a local daemon’s cache, or if a daemon can or will answer its own Interests.) These issues are now part of the design dialogue for the NDN reference implementation.
- Key Management / Certificate-style Features: One of the most significant open areas being informed by the application requirements are the mechanisms for key publishing, management, and conventions for establishing trust relationships. For now, each application is developing its approach to trust somewhat independently, in dialogue with the security team. The security team is then exploring standard trust delegation mechanisms that synthesize these needs, and suggest best practicies by, for example, being name hierarchy-aware but not hierarchy-dependent. From the results of this work, and as design patterns are clarified, architectural conventions (including the role of the currently undefined “certificate” field in ContentObjects) and reference implementation support will be developed by the architecture team.
- Key Generation and Storage: The current approach to public key generation and storage lacks the flexibility and features needed by the applications. An example is the key-per-unix-user convention in the CCNx libraries, which does not map well to the applications under development. A near term action item for the applications team is to articulate needs for key generation and storage for consideration in the reference implementation. Also, the project team will work together to consider an appropriate approach to key storage and distribution, likely drawing from the approach taken in current TPMs.
- Fast Signature Alternatives: Low-latency applications appear that they may require alternatives to public key signature verification; as a result the team is considered HMACs for this use, which requires reference implementation support and addition to the protocols. Performance tests of the impact of public key signatures as used in different applications will be performed as part of this work.
- Dynamic Routing: Automatic namespace registration and DHCP-style discovery of upstream connectivity has not yet been implemented in the architecture. This is a requirement for real deployment; scenarios developed by the application team will inform this architecture research.
- Encrypted Names: Because names are opaque to the architecture, encrypted names, which could be required to prevent data leakage through names in several of our driver applications, can be implemented without requiring architectural changes. However, conventions for encryption and/or tags indicated for name encryption may require adjustments to the architecture.
- Change in canonical application diagram: Many of our early discussions of NDN focused on the example network topology shown in Figure 2.5. Our application experimentation suggests that the common example should be expanded to include sources from different AS publishing into the same namespace (Figure 2.6) and mobile sources (Figure 2.7).
Additional Results of Application Research
In addition to results directly impacting architecture, the applications research has results that relate to the use of NDN and the CCNx reference implementation, which may in the future influence architecture, conventions atop that architecture, and its overall usability.
- Mobile Publishing: The common case of mobile publishers in participatory sensing applications will drive the development of conventions (and possibly architectural enhancements) for supporting publishing into namespaces that are “remote” from the publishers’s immediate upstream connection.
- Local Named Data Support: To support application developers in using named data, we will need to develop libraries to support the creation and automatic synchronization of named data tied to programming language object primitives. (Some of this functionality already exists in the CCNx Java API.)
- Hash Spaces and Encrypted Names: Applications like the PDC may commonly publish using encrypted names or into hash-based namespaces from the connectivity provider. More work is necessary to explore mappings between these namespaces and applications.
- Manufacturer-supplied Names, Discovery Conventions: Embedded devices will likely be shipped pre-configured to publish prefixes and/or make startup queries in a standardized namespace – conventions for this will need to be considered.
- Application-level Time Synchronization: We expect that our media control application (and other applications) will require mechanisms for application-level time synchronization that can take advantage of NDN functionality; further work in this area is required.
- Encryption-based Access Control: The NDN convention of encryption-based access control (which turns access control into a key management challenge) seems appropriate to our application. Conventions need to be developed to make the mechanisms more consistent across applications and see if additional architectural support can be provided. .
- Namespace-Based Capability Assignment: Similarly, we are experimenting with using the namespaces in which keys are (re)published to assign capabilities to those keys, based on feedback from PARC. If this is successful, architectural or library support may be quite helpful.
- Adapting Client-Server Applications: For traditional client-server based applications, it appears that many can be adapted to NDN networking by modifying the server, so that client and server can run on the same physical host, communicating with TCP/IP (no modification on client needed); then, adapted servers communicate with each other using NDN in a peer-to-peer context.
Reference Implementation Feedback from Applications
Finally, based on initial experience in application deployment, the application group has also been able to provide feedback on the CCNx reference implementation, some of which is listed below.
- The CCNx daemon may benefit from a plug-in model, such as that of wireshark, apache, and many other applications. This would allow shared libraries between developer community that extend CCND instead of living ‘on top of’ or otherwise modifying ccnx core in non-standard way. This would then also allow an easy way to gauge what to include in ccnx core by essentially allowing evolution of a runtime ‘services’ layer between ccnx and application. examples of a plugin could be device discovery, enhanced cryptography, key-stores, etc.
- The CCNx library code may not be very efficient when there are many pending Interests. For example, the audio conference tool sends out many pending Interests to fetch voice packets as soon as they are generated. This requires a lot of CPU usage in the current library.
- The current CCNx library is not thread-safe. This is likely by design for efficient processing of the event loop, but should be discussed in the context of supporting more commonly multithreaded applications and languages.
- Finally, the applications team is working on Python bindings for the C language libraries as an alternative to the C and Java libraries. These bindings will closely represent the data structures in the architecture in Python objects, and enable rapid prototyping of applications that are still experimenting at a relatively low-level-i.e., close to the packet formats.
2.1.3 Related Work
Burke, J., Estrin, D., Hansen, M., Parker, A., Ramanathan, N., Reddy, S., and Srivastava, M. Participatory sensing. In World Sensor Web Workshop (2006), Citeseer, pp. 1-5.
Chang, J. K.-T., C. Liu, S. Liu, and J.-L. Gaudiot. 2011. Workload Characterization of Cryptography Algorithms for Hardware Acceleration. In Proceeding of the second joint WOSP/SIPEW international conference on Performance engineering (ICPE ’11). ACM, New York, NY, USA, 381-390. DOI=10.1145/1958746.1958800 http://doi.acm.org/10.1145/1958746.1958800
Eppstein, D., M. T. Goodrich, F. Uyeda, G. Varghese. Whatís the Difference? Efficient Set Reconciliation without Prior Context. SIGCOMMí11, Toronto, Canada, August, 2011. It provides an example of audio communications over NDN.
Jacobson, V., D.K. Smetters, N. Briggs, M. Plass, P. Stewart, J.D. Thornton and R. Braynard, “Networking Named Content”, ACM Conextí09.
Jacobson, V., D.K. Smetters, N. Briggs, M. Plass, P. Stewart, J.D. Thornton and R. Braynard, “VoCCN: Voice Over Content-Centric Networks”, ACM ReArchí09.
Jang, K., Han, S., Han, S., Moon, S., and Park, K.. Accelerating SSL with GPUs. SIGCOMM Comput. Commun. Rev. 41, 1 135-139. DOI=10.1145/1925861.1925885 http://doi.acm.org/10.1145/1925861.1925885
LBL. Conferencing tools for MBones provides inspirations. http://ee.lbl.gov
Mun, M., Hao, S., Mishra, N., Shilton, K., Burke, J., Estrin, D., Hansen, M., and Govindan, R. Personal data vaults: a locus of control for personal data streams. In Proceedings of the 6th International Conference (2010), ACM, p. 17.
Ortiz, J. and Culler, D. “A System for Managing Physical Data in Building,” Department of Electrical Engineering and Computer Sciences, University of California at Berkeley, Technical Report No. UCB/EECS-2010-128, September 28, 2010. http://www.eecs.berkeley.edu/Pubs/TechRpts/2010/EECS-2010-128.html
Stoica, I., R. Morris, D. Karger, M. F. Kaashoek, H. Balakrishnan, Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications. SIGCOMMí01, San Diego, August, 2001.
Vaughan, J. A., and Millstein, T. Transducer-based personal data vaults: A principled architecture for controlled data sharing. Working Paper, 2011. (UCLA)
2.1.4 Publications
- Shen Li, Tarek Abdelzaher, Mindi Yuan, “Temperature-aware Power Allocation in Data Centers with Map-Reduce”, In Proc. International Green Computing Conference (IGCC), Orlando, Florida, July 2011.
- Zhenkai Zhu, Sen Wang, Xu Yang, Van Jacobson, Lixia Zhang. “ACT: An Audio Conference Tool over Named Data Networking”, ACM ICN Workshop 2011, Toronto, Canada.
- Tarek Abdelzaher, “Green GPS-assisted Vehicular Navigation”, Handbook of Energy-Aware and Green Computing, Chapman & Hall/CRC, expected in 2011. (Book Chapter)
- Md Yusuf Sarwar Uddin, Hongyan Wang, Fatemeh Saremi, Guo-Jun Qi, Tarek Abdelzaher and Thomas Huang, “PhotoNet: A Similarity-aware Picture Delivery Service for Situation Awareness”, IEEE Real-time Systems Symposium (RTSS), Vienna, Austria, Nov 2011.
- Lu Su, Yong Yang, Bolin Ding, Jing Gao, Tarek F. Abdelzaher, and Jiawei Han, “Hierarchical Aggregate Classification with Limited Supervision for Data Reduction in Wireless Sensor Networks”, ACM Sensys, Seattle, WA, Nov 2011
2.2 Routing
|
2.2.1 Objectives
The goal of NDN’s network layer is to provide a name-based packet delivery service for applications to build upon. To meet the requirements of the future Internet, the network layer must have the following properties:
- Scalability: support a large Internet topology and large number of name prefixes.
- Security: provide integrity, provenance, and pertinence of routing messages.
- Robustness: detect and recover from packet delivery problems quickly.
- Efficiency: exploit multi-path forwarding and data caching for efficient use of network resources.
The network layer has both a routing plane and a data plane as in today’s IP-based Internet architecture. However today’s Internet puts all the intelligence and control in the routing plane1, and leaves the data plane to simply forward packets based on the routing table. The fact that today’s data plane is entirely stateless leads to two undesirable consequences. First, there is no feedback from the data plane to routing, leaving the latter to perform its own fault detections instead of deriving faults from observing the data plane performance. Second, routing cannot detect data packet looping once it occurs, all existing routing protocols are limited to use single path for each destination, instead of utilizing multiple paths. Over the years the efforts to enhance routing performance have led to a complex routing system that is unwieldy to operate and difficult to scale.
In NDN, the forwarding process is adaptive as we will explain in Section 2.3. It monitors the data plane packet delivery performance, detects network problems quickly, and is able to exploit multiple paths and data caching. This intelligent data plane helps reduce routing’s role to maintaining long-term network topologies and policies only, making it simpler and more scalable. Therefore, our research in the routing area focuses on scalable and secure routing protocols, and our research in forwarding strategy (see Section 2.3) focuses on robust and efficient packet delivery.
2.2.2 Technical Approach
Our plan includes implementing and deploying a working solution at the early stage of the project to enable the operation of the NDN testbed, and to gain operational experience from name-based routing. At the same time, we also conduct long-term research on building scalable and secure NDN routing protocols, and eventually implement and deploy them at a later stage of the project.
Extending Existing Routing Protocols
For the initial roll-out of NDN, we extend existing routing protocols, including OSPF (intra-domain) and BGP (inter-domain), for NDN testbed. These protocols have been carefully engineered through many years of usage; they provide a solid foundation for a working NDN routing solution. The extensions to support name-based routing are mainly two-fold: supporting name prefixes in routing updates and routing tables, and providing multiple paths for packet forwarding. The mechanism to implement these extensions is protocol specific and needs research. Once they are nailed down, these routing protocols can be deployed on the testbed to replace currently manually configured routing tables. From operating these protocols in real networks and with real application traffic, we can learn how a name-based routing protocol works in the wild, what new problems emerge, and what functionality that may be missing, and collect such feedback into our research on long-term solutions for scalable and secure name-based routing protocols.
Achieving Routing Scalability
We have planned two long-term research directions to scalable routing: one using provider-assigned names to facilitate route aggregation, and the other exploiting the small-world property that is expected to emerge in a large-scale deployment.
Approach 1: ISP-based Name Aggregation This approach has two basic components: (a) hierarchical provider-assigned names to facilitate aggregation; and (b) a mapping service to map user-selected names to provider-assigned names. This approach can result in the FIB size being proportional to the number of ISPs rather than the number of users or data sources, the routing scalability is similar to that of separating core and edge prefixes we proposed for IP routing scalability in a previous NSF project [54,47]. We also plan to investigate the feasibility of local FIB aggregation, an effective mechanism to scale IP forwarding tables that was developed in the same project [79].
Conceptually, provider-assigned names are similar to provider-assigned IP addresses, but unbounded in size. For example, a user at AT&T may be assigned the name/att/location/user. These names can be aggregated to /att/location and ultimately to /att. Alternatively, users may choose names that are easier to remember,e.g., /aliceblog, and use a mapping service to map the name, or name prefix, to a provider-assigned name, e.g., /att/atlanta/alice/blog. For Bob to read Alice’s blog, Bob’s computer will use the mapping service to retrieve the provider-assigned name (or names) for /aliceblog.
Two architectural features of NDN can profoundly reduce the incentive for networks to de-aggregate or otherwise inject longer name prefixes into the global routing system. First, NDN’s native multipath forwarding capability provides natural support for multihoming, and its inherently symmetric routing – Data is only sent back traversing the Interest path – allows routers to monitor “path” performance by maintaining per-interface throughput statistics, and adapt forwarding path (interface) selection strategy accordingly. Second, NDN naturally secures all routing updates. These two factors remove the incentive of IP prefix de-aggregation to support traffic engineering or to reduce the chance of being hijacked.
To map user-selected names to provider-assigned names, we augment the existing DNS system with a new NDN resource record containing the mapping information, possibly under a new top-level domain .ndn to hold the mappings for user-selected names, e.g., aliceblog would map to aliceblog.ndn.
Approach 2: Exploiting the Name Space and Network Structure to Scale Routing We are also investigating how to perform network routing directly on application names without resolving them to provider-assigned names. The NDN architecture is sufficiently flexible to allow us to investigate the most ambitious routing research that emerged from our previous NSF FIND project: greedy routing based on underlying metric spaces. Assuming routers can be assigned coordinates in a name-based metric space, they can compute the name-space distances between their directly connected neighbors and the destination name in the Interest packet. In standard greedy routing, each intermediate router then forwards the Interest packet to its neighbor router closest to the destination name. The key to the scalability of this approach is the hierarchical, or tree-like, name space structure. Even an approximately tree-like structure can be mapped to an underlying hyperbolic metric space [35], which we have recently shown supports theoretically optimal routing performance characteristics when greedy routing is used [51,50,67]. Unfortunately, standard greedy routing does not always succeed in reaching the destination [9], sometimes getting stuck at local minima, i.e., routers having no neighbors closer to the destination than themselves. We overcome this problem by augmenting standard greedy routing with elements of random walks, and evaluate the cost to path length. Specifically, intermediate routers can forward Interests not only to the neighbor closest to the destination, but to any neighbor with high probability of being closer to the destination. This approach is particularly suited to NDN’s native multipath forwarding capability at the data layer. It is also conceptually similar to emerging “social overlay” routing in a variety of networks [21,57,43,58,16,59] where the destination of information propagation is a specific individual or content. Forwarding decisions rely on social distances to the destination, while network connectivity is provided by the highly dynamic “underlay network.” In our case, the underlay network is the NDN router network, and the hierarchical name space serves as a type of social overlay.
Remaining open research questions include: (1) how routers can compute the name-space coordinates using only local information in their FIBs, PITs, and/or Content Stores, and potentially the name-space coordinates of their neighbors; (2) how routers can optimize their performance with probabilistic random walk behavior; (3) determining specific properties that the structure of the name space and router topology must have to ensure efficiency; and (4) what mechanisms might induce these properties as the NDN network grows.
Securing Routing Information
A secure routing system is an important part of trustworthy networks. Routers need authentic and truthful routing information in order to make proper routing decisions for packet delivery.
Unlike current Internet for which routing security is an afterthought and optional, NDN provides basic building blocks for comprehensive routing security at the architecture level. In NDN, every Data packet, including routing messages, is signed by the producer of the packet content. Thus by verifying the signature using trusted keys, a receiver can confirm the message’s integrity (i.e., it has not been altered) and provenance (i.e., it was generated by the claimed producer). Also since Interest and Data carry names, the receiver knows the message pertinence (i.e., it is what the receiver is interested in).
One can build a comprehensive routing security solution with the above routing message integrity, provenance, and pertinence. In case of forged, altered, or outdated routing messages being injected by outside attackers, they can be easily detected and discarded. In case of legitimately signed messages sent by compromised inside routers and containing false information, the receiving router can cross check the information with what it receives from other routers, and any inconsistency indicates a potential problem. Even if an insider attack succeeds, the potential damage is limited because every router or routing element is only allowed to sign updates for a predefined subset of the namespace, usually referring to the networks that are directly connected to its own interfaces. When the number of compromised routers is small, the chance of catching the attack is good. When the network grows larger, routers can collect a rich set of authenticated routing information from many different paths, thus the attacker’s job of avoiding its false content from being detected becomes exponentially harder. Thus, strong routing security becomes an emergent property of large networks with rich connectivity.
In order to achieve secure routing using the NDN building blocks, we need to answer three major questions. First, how to name the participants and the messages in a routing system? This naming convention forms the basis of the design, and directly relates to the security features, key management, and fault diagnosis. It must also take into account network operations, e.g., the distinction between intra-domain routing and inter-domain routing may require different naming schemes. Second, how to retrieve, verify, and manage keys? Because routers need trusted keys to verify Data signatures, key verification is a critical part of the system design. Third, once a router has collected a rich set of signed routing data, how does it manage and correlate the information in order to decide on the truthfulness of incoming messages? Routers need good understanding of the information it has collected in order to detect any inconsistency that may exist in incoming messages. If a message with false content is detected, the system needs to identify the root of the false content and contain any potential damages.
To assure rapid progress, we are taking a two-step approach. We first explore the design in intra-domain routing, where a single trusted party exists, and we can focus on basic design issues such as naming conventions and key management. We then extend to inter-domain routing where no single trusted party exists, and focus on deriving trust and ground truth routing information by integrating inputs from a variety of sources.
The research effort on routing security is coordinated among the routing group, security group, and network management group within the NDN project.
Bootstrapping Edge-node Connectivity
One of the initial deployment problems in NDN testbed is how edge nodes get configured to connect themselves to a larger NDN overlay for connectivity beyond the local LAN. To address this problem, we implement a prefix announcement scheme for end-hosts to automatically discover NDN routers. As a limited and very specialized case of propagating routing information, this made a good place to start on routing implementation.
Activities When an end-host connects to a network, it sends out an Interest packet for local bootstrap information. This Interest packet can be either broadcast to all nodes or multicast to all NDN nodes in the local network. The local NDN server replies with a Data packet containing the necessary information for the client. This reply can be broadcast, multicast, or unicast to the client. The actual content of the data, as of now, is a default routing entry that contains the default router’s layer-2 address and the default name prefix “/”. It should be an easy extension to add additional specific external name prefixes into the Data packet. As we gain more experience in what bootstrap information applications may need, other types of information can also be added to the bootstrap reply message, making this a general mechanism to bootstrap end-hosts with knowledge about the local network environment.
We have implemented the above functionality and tested it in a local lab environment as well as in the Washington University ONL testbed (see Section 2.4). As of this writing, we are testing this program at other sites within the NDN project.
Findings We are still in the early stage of exploring the design space of network connectivity bootstrapping along the named-data direction. One thing we have firmly grasped is that it is of critical importance to fully utilize the broadcast nature of any local communication medium in the bootstrapping process, to support end devices that become increasingly mobile and wirelessly connected.
This new way of thinking directly contrasts with existing bootstrapping practices in two fundamental ways. First, each end device today must first obtain an IP address assignment from some infrastructure service before communications can begin, while devices in an NDN network communicate using data names directly. Second, and related, broadcasting Interests with data names enables devices to communicate directly to find the nearest copies of the desired data without necessarily involving a router. We understand that there may be concerns regarding the efficiency of broadcast in a switched environment (e.g. a switched Ethernet), we believe these concerns can be effectively addressed through a careful design of the forwarding strategy layer, a unique new component in the NDN architecture.
Next Steps In the coming year we will develop this program into a general-purpose bootstrap utility for nodes and applications, and deploy it across the NDN testbed for regular use.
- Complete field tests on the testbed, improve the program based on feedbacks, release for regular use in the NDN network. This step is expected to take one to two months.
- Make any node in the LAN able to reply the query, and the querier be able to choose the most recent, authenticated reply. Design and implement effective duplicate suppression algorithms.
- Design and implement a flexible Data format based on XML to accommodate different application needs.
OSPF Extension
As the deployment of RIP, OSPF, IS-IS and BGP have demonstrated, link-state routing protocols can provide better support for multi-path routing, faster convergence, and easier diagnosis than distance/path vector protocols. Therefore, we choose to extend OSPF to implement the first name-based routing protocol.
Activities and Findings We look into the details of OSPF specification to design the extensions for NDN, which we call “OSPF-N.” We have finished the design document of OSPF-N, set up a lab testbed, and done various feasibility tests of the implementation techniques.
The OSPF-N configuration manager at each NDN node configures links to other NDN nodes, name prefixes of the content store, and the maximum number of hops to be calculated for each name prefix in order to support multipath routing. Each NDN node will run CCNd and OSPF-N in parallel, and use two new types of Opaque LSA’s (Link State Advertisement) to carry adjacency information and name prefix information, respectively. This design allows incremental deployment since legacy IP routers, which do not understand the new opaque LSAs, would simply forward them to neighbors without causing any interruptions.
The Opaque Adjacency LSAs are used to dynamically build and maintain the NDN overlay network topology at each NDN node. Each NDN node constructs an NDN routing table from the overlay topology’s shortest path tree. Opaque Adjacency LSAs are created from the configuration file at each node to contain information about the node’s NDN neighbors, which is connected via either a direct physical link or a configured tunnel through IP networks. OSPF floods each NDN node’s Opaque Adjacency LSA, and each NDN node will build a complete NDN network topology based on the LSAs it has received.
Opaque Name LSAs are used to advertise content name prefixes originated by an NDN node. As each NDN node parses the names to be advertised in its configuration file, it builds Opaque Name LSAs and injects them into OSPF to be flooded. With this approach each NDN node can dynamically build the network topology, and calculate the next hop for each reachable name prefix. The node then builds its routing table and exports it for CCNd to use in packet forwarding.
We have set up a testbed with three workstations installed with Ubuntu Linux. Both CCNd and the Quagga OSPF suite were installed on each workstation. We created tunnels among the workstations to connect them and conduct research activity with different configurations. The Quagga OSPF suite provides an API to inject/delete/update Opaque LSAs in the OSPF routing daemon. In our research, we tested injecting Opaque LSAs with name prefix information from one workstation into the testbed, and it was verified that they were flooded to the entire testbed, and other workstations were able read them from OSPF. We have also tested that once OSPF-N builds a routing table, it is able to export it to CCNd for packet forwarding.
Next Steps We set forth the following major milestones for OSPF extension during next year.
- Implement OSPF-N, test and debug. Aim for initial release at the end of year 2011.
- Once the intra-domain routing security design is ready, implement the security mechanisms into OSPF-N.
- Maintain OSPF-N based on feedbacks from the NDN testbed usage.
- Explore the ISP-name based approach to scale routing tables.
Routing on Hyperbolic Metric Space
Activities For long-term scalable routing solution based on name spaces and network structures, we studied routing on hyperbolic metric space. To enable the greedy navigation component in network routing, we must be able to efficiently compute the coordinates of nodes in the network – a task we call network embedding. The embedding algorithms in http://dx.doi.org/10.1038/ncomms1063 are unlikely to scale to the characteristic sizes of router-level Internet topologies. The first method we explored was estimating the underlying distances between nodes based on estimated number of common neighbors between nodes, which requires an analytic expression for this number, given the degrees and distance between a node pair in the model described in http://dx.doi.org/10.1103/PhysRevE.82.036106. We also worked on deriving the expression for the distance vs. the number of common neighbors for the case with strongest clustering, but essentially failed there: the problem turned out to be too combinatorially complicated and became intractable. This is a bit concerning since for now we have an expression (and, consequently, can infer distances) only for networks with one specific value of the clustering strength. Luckily, this clustering strength is approximately what is observed in the Internet AS-level topology, but if other types of topologies (e.g., router-level) have significantly different clustering values, then we are stuck, that is, the inferred distance values may be too approximate. In this context we also began looking into the properties of (single AS) router-level topologies, to estimate how accurately our models can approximate these topologies. Another approach to distance estimation is an extension of the work in http://dx.doi.org/10.1109/INFCOM.2010.5462131, where we consider networks growing in hyperbolic spaces. The model there requires adjustments to allow for fixed or Poisson values of initial node degrees. Assuming we have such a realistic model that matches the evolution of a real network such as the Internet, we can then estimate distances between nodes from the evolution history of the network.
Findings We obtained the analytic expression needed to estimate the number of common neighbors between nodes, inverted it for angular coordinate estimation in a given real network, and applied it to synthetic networks in our model to estimate distance between nodes in the underlying metric space from the number of common neighbors between the same nodes in the network. Unfortunately, we could accurately predict underlying metric distances only between nodes with many common neighbors (i.e., nodes close to each other in the metric space). For nodes located far apart, we observed too much fluctuations in distance locations, essentially precluding any distance estimations. We achieved a clean formulation of a growing network model, with nice controls for all network properties in the model, and rough analytic estimates and simulations. The key finding is that the speed of node expansion in the hyperbolic space affects the exponent of the degree distribution. We also established very nice connections between our model and standard preferential attachment, corresponding to the configuration model in the static case. We also mostly finalized how to tune clustering in generated network. Most importantly, the validation using the history of growing Internet confirms the prediction very nicely. It was a lot of work showing that, as we had to embed each Internet time-snapshot from scratch. We used Dhamdhere’s temporal Internet topology data, and our existing embedding algorithms from the last paper in Nature.
Next Steps
- Explore other approaches to constructive embedding. Specifically, we have recently observed that the following simple modification to the constructive embedding procedure improves its results significantly. Instead of estimating the similarity distances between nodes based on the common-neighbor statistics for the whole network at once, we can perform this estimation in stages, starting from the densest core of the highest-degree nodes, and then adding groups of lower- and lower-degree nodes, keeping the coordinates of already-embedded nodes fixed, conceptually similar to the embedding rounds inhttp://dx.doi.org/10.1038/ncomms1063. For simplest synthetic networks, the improvement in greedy routing success ratio due to this modification is quite impressive. We plan to apply it to some real networks, and check if it can yield acceptable results.
- Finish the work on growing networks. We plan to validate the model’s predictions for network evolution against a few other growing complex networks, thus strengthening the evidence for the universality of the model, and increasing the plausibility that it will be applicable to an NDN Internet.
- Try out greedy routing on the NDN testbed. Specifically, the idea is to take the hyperbolic coordinates of the ASs in the testbed as computed inhttp://dx.doi.org/10.1038/ncomms1063, and then use them for greedy routing in the testbed, which is a network overlaying on top of the AS topology. Although this approach may or may not work well due to a number of reasons (e.g., the network is small), we should be able to easily adjust the AS coordinates to achieve optimal routing characteristics, which may inform us what type of adjustments to greedy routing are needed in general, and node coordinates in particular, if greedy routing based on hyperbolic similarity namespaces is used in a real NDN Internet.
Routing Security Model
Activities We have completed an initial routing security model design based on the ideas of named data and topology-derived trust.
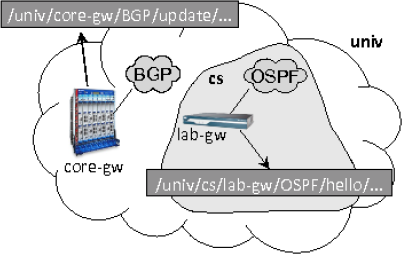
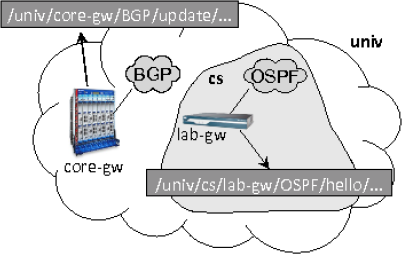
First, following the basic principle of named data design, meaningful and hierarchical names are assigned to all components in the routing system, including networks, routers, router interfaces, and routing processes, where the name hierarchy naturally reflects the structure of the routing system. Each component also has a public-private key pair, which is used to sign routing messages or certify other keys in the system. For example, a BGP update that is originated from a university’s core router may get a name like /univ/core-gw/BGP/update/..., and an OSPF HELLO message in a backbone area of a CS department network may get a name like/univ/cs/lab-gw/OSPF/hello/... (Figure 2.8). Our current naming convention for routing components is to name the network hierarchy first, then the individual device box, followed by the process ID and any application specific components. Internally used names are not necessarily visible externally. For example, in a large ISP, OSPF messages may carry names with geographic location information of the routers; such information is accessible only inside the OSPF instance and should not propagate beyond the ISP’s scope.
Second, our design derives trust of public keys from existing topological relations that are based on contractual and physical adjacencies between organizations and routers, rather than depending on a third-party infrastructure extraneous to the routing system. In intra-domain routing, since everything is under the same administrative control, all trust can be derived from the organization key, which is generated by the organization’s network operator and configured into all the routers. Starting from the organization key, other keys, such as router/interface/process keys, can be certified via a chain of trust.
In inter-domain routing, instead of relying on the assumption of a globally trusted central authority as in most PKI-based designs, our design leverages the contractual relationship between autonomous systems (AS) to locally control and administer trust. Provider networks sign public keys of their immediate customers, and peer networks sign the keys of each other. This process is illustrated on Figure 2.9. “Tier-1” ASes 1 and 2 sign each other’s keys. AS 1 signs keys for AS 3 and 4, AS 2 signs key for AS 7, and so forth. To verify keys, networks can rely on only direct providers or peers (in example on Figure 2.9, AS 5 relies on AS 3’s authority, but AS 4 relies on AS 1, 2, or 3). This essentially gives a method of public key management that can be universally applied on every level of routing without violating any principles of network organization.
However, this universality comes with a price: we need to introduce one more level of certification in the reverse direction of topological relations. If a network knows only its direct provider’s public key, it cannot verify certification chains that start beyond its direct provider. In our example on Figure 2.9, AS 5 needs to give its customers certification of AS 3’s key, and AS 3 needs to provide AS 5 with certificates of AS 1 and AS 4’s keys. One level of this reverse topological signing is enough to build a certification chains throughout the hierarchy. If AS 5’s customer knows AS 5’s certification of AS 3’s key and AS 3’s certification of AS 1’s key, it can verify any chain that starts from AS 1’s key.
The distribution of keys and certificates can be done both “in-band” or “out-of-band.” We can use the existing distribution mechanisms in routing protocols, e.g., use OSPF’s LSAs or BGP’s routing announcements to carry the keys and certificates. We can also use DNSSEC to securely distribute them.
 |
 |
Findings Our initial effort in developing a secure routing system exhibits two fundamental departures from the existing literature in secure routing system designs. First and foremost, we fully utilize the named-data approach: routing updates are simply data of a special type, every piece of data carries a semantically meaningful name, and every name is associated with a cryptographic key pair. In fact in today’s operational practice, network operators have been using well established conventions to name routers in a hierarchically structured name space that reflects the hierarchical structure of the network. We formalize this established operational practice, extend it to cover every routing component, and also use it to name routing updates as well as to secure them.
The second new approach in our initial routing security design is the utilization of topological adjacency relations between routers and networks to establish cryptographic relations. It leverages the rich connectivity in the Internet for better resiliency against attacks. Traversing the topology-based certificate chains, a router/network has multiple paths to verify a key. Even if one or two paths encounter problems or are compromised, one can still obtain valid updates through other paths. As the network grows larger and becomes denser, the resiliency against attacks will also increase exponentially. The use of a cryptographic key trust model (that follows topological connectivity) and signed routing updates allow us to provide an effective protection against malicious outsider attacks. To minimize the potential damage by malicious insiders to the routing system, we limit each router to sign only updates for a predefined subset of namespaces, specified by the root of trust in a network or by its direct descendants but not by the router itself or its peers. In this way, a compromised router will only be able to issue false updates that refer to networks that are directly connected to its own interfaces.
Next Steps Our plan in the second year is to flesh out all the details of routing security design, and start the implementation and deployment in intra-domain routing on the NDN overlay testbed.
- Take OSPF as an example, flesh out all the design details for a working solution of intra-domain routing security.
- Work with the OSPF-N team to implement and conduct trial deployment of the secure OSPF-N on the testbed.
- Evaluate the effectiveness and feasibility of topology-derived trust under inter-domain routing. Evaluation will be done in the form of simulation and attack analysis.
2.2.3 Publications
- Cheng Yi, Alexander Afanasyev, Lan Wang, Beichuan Zhang, Lixia Zhang, “Adaptive Forwarding with Stateful Data Plane,” submitted to the ACM Workshop on Hot Topics in Networks (HotNets), 2011.
- Alexander Afanasyev, Lan Wang, Beichuan Zhang, Lixia Zhang, “Securing routing via named data and topology-derived trust”, submitted to ACM Workshop on Hot Topics in Networks (HotNets), 2011.
- Serrano, M. Krioukov, D. Boguna, M., “Percolation in Self-Similar Networks”, Phys. Rev. Lett., p. 048701, vol. 106, (2011). Published, http://dx.doi.org/10.1103/PhysRevE.82.036106
- F. Papadopoulos, M. Boguna, and D. Krioukov, “Popularity versus Similarity in Growing Networks”, http://arxiv.org/abs/1106.0286, (2011). Submitted.
2.3 Forwarding Strategy
|
2.3.1 Objectives
Forwarding strategy is a novel concept introduced by NDN. Unlike in an IP network where the forwarding process simply looks up the routing table to direct traffic, NDN’s forwarding process can adapt its forwarding decisions based on the inputs from both routing tables and data-plane observations. This adaptive forwarding with stateful data plane changes the network layer in a fundamental way. Our research objectives is to develop forwarding strategies for robust packet delivery and efficient use of network resources, and also to develop techniques that reduces the state overhead.
2.3.2 Technical Approach
Robust Packet Delivery
Delivering packets is the most fundamental function of the Internet. Ideally networks should continue to deliver packets even in the presence of unexpected failures as long as destinations are still reachable in the remaining topology. This system robustness in face of component failures is referred to as “perfect switching” in Paul Baran’s seminal work [7]. In IP, since the routing plane makes all the forwarding decisions with little or no input from the data plane, it may take time to detect faults (e.g., link failures), mis-interpret faults (e.g., treating congestion as link failures), or may not even be able to see the fault at all (e.g., prefix hijacking), resulting in today’s Internet being far from perfect switching.
At NDN’s data plane, packets flow in both directions, with Interests and Data taking symmetric paths and maintaining one-on-one flow balance. Since each NDN node maintains per-packet state in PIT, it can observe data-plane performance, detect problems, and adjust forwarding decisions. An Interest serves as a data probe with one of three possible outcomes: (a) a returned Data packet; (b) a returned Interest as a negative acknowledgment; or (c) a timeout signaling a packet loss. These feedbacks arrive within the time scale of an RTT, thus a node can detect network problems quickly. Once a problem is detected, a node can freely explore other paths because it does not worry about loops. Therefore an NDN network can outperform IP in terms of successfully delivering packets in face of various network faults. Good forwarding strategies should find working paths that go around failures in a short time period with little overhead. The research questions include which interfaces a node should probe and when in order to achieve the most robust and efficient data delivery.
Efficient Use of Network Resources
Efficient use of network resources has been a long standing problem in networks. The answer in today’s Internet is mostly MPLS-based traffic engineering. Due to its loop-freedom and data-plane feedback, NDN is able to use multiple paths to forward traffic, a great capability that can lead to automatic, distributed solutions for efficient use of network resources [76]. However one must also answer the question of when to use multiple paths and how to choose the best ones.
One option is to use multiple parallel paths only when needed. For example, when a single best path can adequately handle the traffic load for a given name prefix, the router may simply stick to the best path, and divert (excess) traffic to other path only after a problem occurs, such as link failure, congestion, or noticeable packet loss. Another approach is to proactively split traffic along multiple paths, so that a router can get feedback on data-plane performance from all the multiple paths, and if a failure occurs, it may affect only a small portion of the traffic. The two approaches are not exclusive of each other, and we investigate both.
Good forwarding strategies would direct traffic to use available bandwidth in the network, spread the load over different paths, and push traffic back to the sender only if the demand is greater than the total capacity of the network, or a particular demand takes more than the fair share of resources. The research questions include which paths to direct traffic to, and how to make adjustment upon feedbacks.
Reducing the State Overhead
NDN introduces per-packet state, which is of the finest granularity in a packet switched network. The advantage of using the finest granularity in control is the versatility to serve all kinds of different purposes. For example, the three problems that we have studied, i.e., link failures, congestions, and prefix hijacking, differ from each other and each has its solutions independent from the others in today’s IP networks. One reason is that different solutions require control state of different kinds and at different granularity. In NDN, they can all be handled by the same forwarding mechanism based on the per-packet state. This greatly simplifies the overall system at the architectural level. It also allows new uses of the state information in the future without incurring changes to the basic mechanism.
The downside of per-packet state is the amount of state. In NDN, since an Interest stays in the PIT until the corresponding Data packet returns, the number of PIT entries is roughly bounded by RTT×Bandwidth/S, where S is the average size of Data packets. As the network gets faster, the PIT table will grow proportionally. The content of PIT is also highly dynamic, as new Interests keep getting inserted into and satisfied Interests removed from it. A router must perform each operation fast enough to keep up with line speed. Storing and maintaining PIT can be challenging in large networks.
We plan to explore techniques that can reduce the size of PIT. One approach is to use bloom filter to summarize multiple PIT entries at each downstream interface. When Data packet comes back, matching Data’s name with the bloom filters can locate the correct next-hop for the Data packet. In case of a false positives, Data will be sent to downstream nodes that did not ask for it. Such extra Data packets would not travel far before being dropped because the probability is very low for the bloom filter false positive to happen along multiple hops. If carefully designed, such technique may be able to trade a small amount of bandwidth for a significant reduction in PIT size.
Activities
During the first year, we have extended NDN’s forwarding design to implement a couple of simple forwarding strategies, and compared their performance with that of IP’s through simulations.
In order to describe a forwarding strategy, we first define face ranking and face availability2. For each name prefix, a FIB entry contains an ordered list of all the faces of the node. The ranking of the faces can be initialized by routing information. For example, if BGP is the routing protocol in use, one can rank the faces by comparing the AS paths stored in all the RIB-INs; with OSPF, one can compute the best path going out via each face and rank the faces by the path metrics. Once data traffic goes through the node, the observed data plane performance will affect the ranking of faces. For example, a packet loss or long delay can move the corresponding face down the ranking.
Each face has an Interest rate limit which controls how fast Interests can be sent so that the return Data packets will not overload the link. Because one outgoing Interest retrieves at most one datum, Data rate in the downstream direction (toward consumers) can be controlled by adjusting the Interest rate in the upstream direction (toward producers). When the Interest rate is below the limit, the face is considered available, otherwise unavailable. The Interest limit can be implemented using some mechanism such as leaky bucket.
When an NDN node forwards an Interest the first time, by default it chooses the highest ranked, available face to use. When the first transmission fails to bring back Data and there is a need to transmit the Interest again, we have examined two strategies to use in this case.
- RANKING: Send the Interest to the face ranked next to the one used in previous transmission.
- RANKING-RETX: Send a copy of the Interest both to the the previously used face and to the face ranked next.
Flooding is another strategy that we examined. Flooding explores all possible paths at once, providing the most robust packet delivery but also incurring the most overhead in terms of duplicate messages and network state. The RANKING strategy explores one path at a time, which may take several trials before finding a working path. The RANKING-RETX strategy forwards the same Interest to two neighbor nodes; one could also send different Interests to multiple different faces at once.
We used the QualNet simulator [71] to evaluate NDN’s forwarding strategies. We implemented in QualNet NDN’s PIT, FIB, Content Store, the basic forwarding logic, and three forwarding strategies (FLOODING, RANKING, and RANKING-RETX). We experimented with Abilene and Sprint’s network topologies to compare IP and NDN’s performance. We have written scripts to create prefix hijacking, link failures, and congestions in the simulation environment, as well as collect traffic statistics after simulations.
Findings
Our simulation results show that NDN is significantly more resilient to network faults than IP. In all three problem scenarios (i.e, prefix hijacking, link failures, and congestion), NDN outperforms IP significantly in packet delivery.
During prefix hijacking simulation with Sprint topology, the attacker blackholes all incoming traffic. IP’s packet delivery ratio ranges from 10% to above 90% in different simulation runs, depending on the relative locations of the sender, receiver, and hijacker in the topology. NDN, on the other hand, can deliver packets 100% with all three forwarding strategies that we have simulated (Figure 2.10). During a hijack, routing does not detect any problem, thus IP forwarding makes no adjustment even when many packet are lost. NDN is able to detect packet losses and explore other paths to deliver packets. Figure 2.11 shows the time that takes each NDN forwarding strategy to retrieve Data. It illustrates the tradeoff between the message overhead and delay. Flooding Interests can retrieve Data with smallest delay but send the most number of messages. RANKING and RANKING-RETX spend more time than flooding to find working paths but send fewer messages. One of the future work is to research other forwarding strategies that leads to a better tradeoff.
|
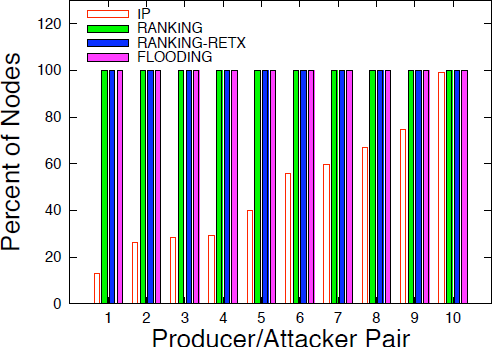
|
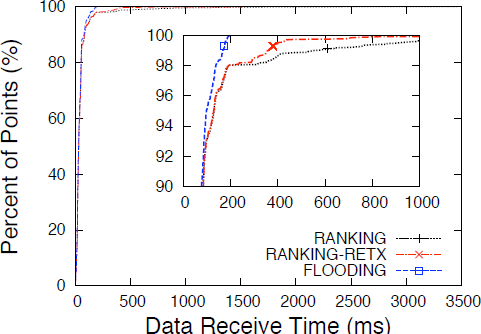
When a link fails, routing may take some time to detect it and converge. Before routing converges, obsolete routing table entries can lead to packet drops. Figure 2.12shows the packet loss rate in Abilene network with different single link failures and 5s convergence time. IP has loss rate from about 5% to 35%, depending on the locations of sender, receiver, and failed link in the topology. NDN’s loss rate is at most 3% and close to 0 in most single link failures. Again, the better packet delivery is due to NDN’s ability to detect packet loss and search for alternative paths without worrying about loops.
|
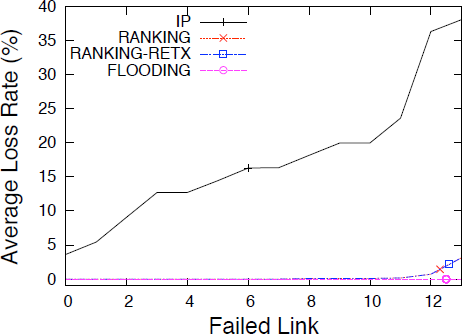
|
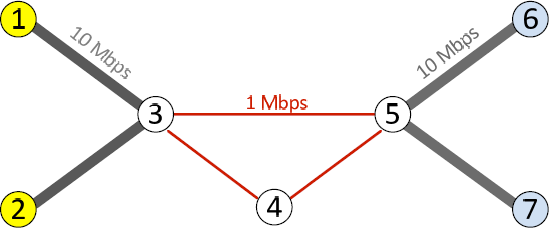
To compare NDN and conventional TCP/IP’s behavior under congestion, we use a simple synthetic topology (Figure 2.13) in which three bottleneck links (3-4, 4-5, and 3-5) have capacity ten times smaller than that of other links. Each simulation models behavior of two data flows transferring 2.5 MB of data-flow 1 from node 6 to node 1 and flow 2 from node 7 to node 2. Transfers start with a 5 second delay relatively to each other (flow 2 starts first). Propagation delays of the links are configured as follows: links 1-3, 2-3, 3-4, and 5-6 have a propagation delay of 1 ms, links 3-5 and 5-7 have a propagation delay of 50 ms. This configuration gives us an RTT between 104 ms and 106 ms for the first flow and 202 ms to 204 ms for the second flow, depending on which bottleneck path is selected. FIFO queues at each node are configured to be able to buffer at most Capacity ×RTTmax bytes (i.e., bandwidth-delay product), where RTTmax is 200 ms.
Figure 2.14 shows the dynamics of observed data throughput for each flow. The top figure is for TCP/IP, while the lower figure is for NDN. We can observe that two NDN flows have an aggregate throughput close to 2Mbps, much higher than the 1Mbps aggregate throughput of the TCP flows. This is because NDN automatically discovers and fully utilizes the two bottleneck paths (3-5 and 3-4-5), while TCP/IP sticks to the single best path (3-5) picked by routing and cannot utilize other paths even when the best path is highly congested. This is more evident in Figure 2.15). NDN is able to fully utilize both paths, while in TCP/IP, one path is fully loaded but the other is idle.
These results, though preliminary, demonstrates clearly the advantages of NDN’s intelligent data plane. Its ability to observe data plane performance, quickly detect problems, and freely explore alternative and multiple paths is the basis for robust packet delivery and efficient use of network resources.
Based on our experience in designing and evaluating forwarding strategies, we propose to add a simple negative acknowledgement mechanism, Interest-NACK, to the NDN design. When an NDN node cannot satisfy or forward an Interest, it returns the Interest back to the downstream node via the same link from which the Interest was received. Therefore in the absence of packet loss or other failures, every pending Interest is expected to be consumed by either a returned Data packet or a returned Interest within RTT. Interest-NACK brings two benefits to the system. First, they clean up the pending Interest state much sooner than waiting for the state to time out, preventing such already failed pending state from blocking new requests for the same name. Second, it notifies the downstream nodes about the upstream problem quickly, enabling recovery action to be taken right away. In fact, an Interest-NACK can carry an error code to identify the reason that it is returned, e.g., link failure, congestion, duplicate Interest, no such Data, and so on. We are currently evaluating the effectiveness of Interest-NACK in multipath scenarios.
|
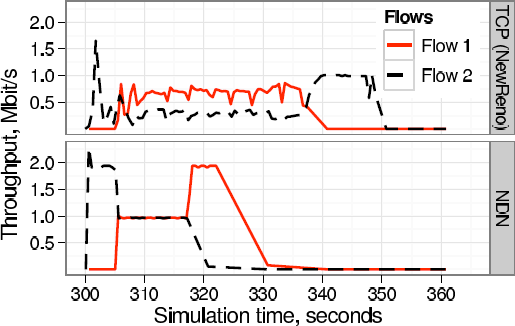
|
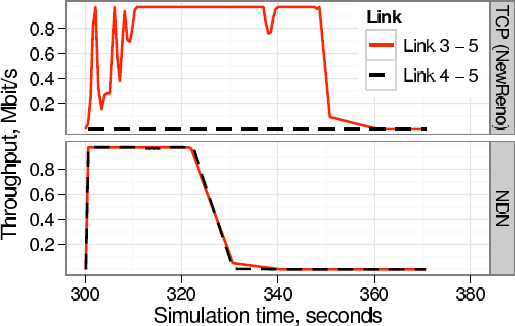
Next Steps
- Implement simplified NDN in ns-3 as an open-source simulator for the use by this project as well as the NDN research community at large.
- Experiment with different forwarding strategy for efficient use of network resources via multipath forwarding.
- Explore solution space to reduce the amount of forwarding state needed.
2.3.3 Publications
- Cheng Yi, Alexander Afanasyev, Lan Wang, Beichuan Zhang, Lixia Zhang, “Adaptive Forwarding with Stateful Data Plane,” submitted to the ACM Workshop on Hot Topics in Networks (HotNets), 2011.
- Cheng Yi, Alexander Afanasyev, Varun Khare, Lan Wang, Beichuan Zhang, Lixia Zhang, “Robust Packet Delivery via Named Data,” Technical Report, NDN-0002, 2011.
2.4 Scalable Forwarding
|
Our results in the first year of the Named Data Networkinging project are focused on scalable NDN forwarding, and can be summarized with the following points.
- We have established a performance baseline of the NDN reference implementation. Washington University’s role in the NDN project is to explore and develop high-speed, scalable implementations of the NDN forwarding plane. The NDN forwarding plane has some unique characteristics relative to IP, and most of the differences represent performance challenges. As described in the proposal, we pursue several algorithmic and implementation directions to achieve speed and scale. However, the initial focus for the first year has been to establish a repeatable baseline of performance for the NDN reference implementation, and at least one related but competing forwarding architecture, in order to compare our subsequent designs and performance gains against a relevant and unambiguous fixed point. Along the way, we roughly doubled the performance of the NDN reference implementation under a set of repeatable experimental assumptions. Our current baseline is below 300 Mbps, and we aim to produce implementations capable of exceeding gigabit rates.
- Our performance measurement work has been enabled through the use of the Open Network Lab. While there are many ways to estimate the performance of networking mechanisms, such as via analysis or simulation, in this project we quantify our performance by measuring operational systems. To do this, we have relied on the NSF-funded Open Network Lab, or ONL, at Washington University to conduct and measure NDN experiments consisting of 10s of routers. Since adding support for NDN to ONL, other researchers have been using ONL to carry out their own experiments in the areas of routing, security, and measurement.
-
We have deployed the NDN reference implementation on 5 Supercharged PlanetLab Nodes within the GENI infrastructure. As an initial step, we have deployed the NDN reference implementation (software-only) on 5 programmable routers with provisioned point-to-point bandwidth across Internet2.
-
We have had a modest start in disseminating our results in traditional academic venues, with one conference publication in year one and several presentations at meetings.
This work has been carried out in the Applied Research Lab at Washington University in St. Louis. The project team consists of Patrick Crowley (PI), Jyoti Parwatikar (research staff), John Dehart (research staff, joined project in June), Haowei Yuan (graduate student), and Shakir James (graduate student, joined project in June).
The following sections describe our first-year work in greater detail.
2.4.1 Goal of NDN Forwarding Research
As described above, our goal in the NDN project is to develop fast, scalable NDN node prototypes. By fast, we mean that we intend to support 1 Gbps links at line-rates in software implementations; we expect our hardware-based, and hardware-accelerated implementations to exceed this rate by at least an order of magnitude. By scalable, we mean that we intend to develop an NDN forwarding plane that can support hundreds of thousands of names, each of arbitrary length. (Our scalability goals are not as explicit as our forwarding rate goals because we aren’t yet confident that we understand the requirements or relevant range of name counts and lengths.)
In addition to producing high-speed, scalable NDN node prototypes, we see two additional primary roles in the broader project. First, we provide feedback to the areas of architecture and routing whenever their design choices might have substantial performance consequences in the data plane. Second, we also need to keep NDN forwarding comparable, with respect to features and performance, to other name-based forwarding schemes.
To see why NDN forwarding is challenge, consider table 2.1.
| IPv4 | NDN | |
|---|---|---|
| Forwarding key | Address | Name |
| Key length | 32 bits | Variable |
| Forwarding rules | LPM | LPM |
| Per-packet READ | Yes | Yes |
| Per-packet WRITE | No | Yes |
Table 2.1: IP versus NDN Forwarding
As can be seen, NDN forwarding requires longest prefix match lookups of variable-length names in large prefix tables that must support per-packet updates. Compared to IP, which by comparison is a read-only forwarding plane with fixed-length forwarding keys, the design challenges are substantial. A discussion of both the specific challenges and the high-performance directions we are pursuing can be found in the original proposal, which we do not repeat here in the interest of brevity.
In order to improve performance, one must first be able to measure. To this end, we have added support to the Open Network Lab in order to enable repeatable, performance-focused forwarding experiments of NDN implementations.
2.4.2 NDN Forwarding Research in the Open Network Lab
ONL is an NSF-funded Internet-accessible networking testbed. In ONL, experimenters design a network topology, configure and optionally program gigabit routers, and control Linux end-hosts. These user interactions are managed through a Java-based GUI that is executed on the user’s machines called the remote laboratory interface, or RLI. Through the RLI, users establish their topologies and make a reservation for the required resources. Unlike many other testbed environments, resources are not shared: routers, links, and end-hosts are dedicated to users for the duration of their experiments. A reservation system is used to ensure fair and timely sharing of resources through time. Figure 2.16 illustrates ONL and the RLI.
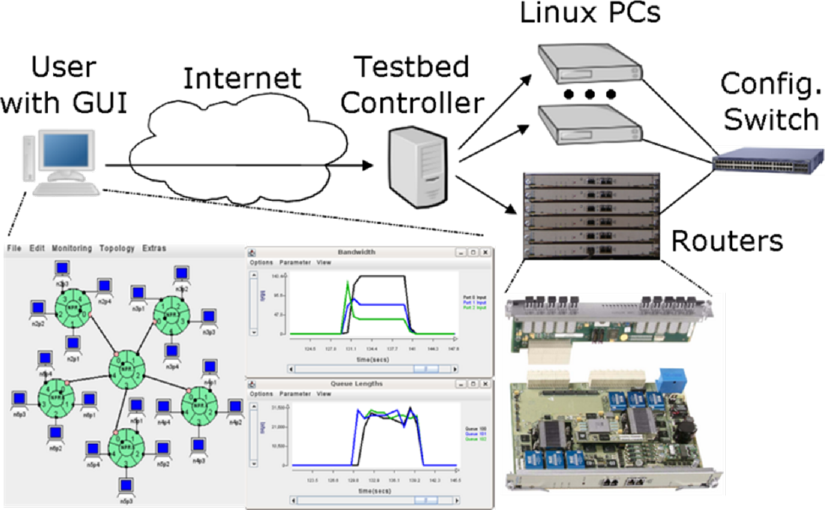
ONL currently contains 14 programmable routers, over 100 Linux hosts, and 1 Gb and 10 Gb links and switches.
To support NDN experimentation, we added a new end-host type to ONL that boots with CCNx, the NDN reference implementation, installed and properly configured. CCNx routes and statistics can be changed and monitored via the RLI. The RLI supports real-time charts, which can be used to report end-hosts characteristics in real-time, including link bandwidth, packets/s, queue lengths, CPU utilization, and memory utilization. ONL accounts and usage are free. Registration and step-by-step CCNx instructions can be found at http://wiki.arl.wustl.edu/onl/index.php/CCNx_in_ONL.
2.4.3 Selection of Illustrative Experiments
To illustrate both our forwarding baseline and usage of ONL, we now present a few experimental results. In particular, we address the following points.
- How does CCNx perform? Over a range of experimental factors, how does the NDN reference implementation currently perform? This forms our performance benchmark against which our high-speed implementations will be compared.
-
How does HTTP caching perform? HTTP caching is a related name-based forwarding mechanisms (in which names are URLs) that is in wide use today. We present a comparable set of experimental results for a modern, commercial-grade HTTP caching system.
-
A modest CCNx improvement. Based on our measurements and understanding of the reference implementation, we discovered a small change that yields a notable improvement in performance.
It turns out that for an application like file distribution, NDN/CCNx and HTTP are remarkably similar. NDN names can be defined to look just like URLs, and NDN networks and HTTP cache hierarchies can be constrained to a tree topology. In both cases, NDN can support other options, but HTTP can not. For our purposes, we want a similar setup so that we can make direct comparisons.
In each experiment, we run a file distribution workload in which some number of client programs download files from a server fronted by a cache hierarchy. The requested names look like {http – ccnx}:/repo/10m.txt/i, i=0,1,2,3,… For our HTTP cache system, we use lighttpd (pronounced “lighty” and used by YouTube and Wikipedia, among others) for the root web server and squid (used by Flickr and Wikipedia, among others) as the caching proxy. We use wget as our web client. For our CCNx experiements, we use a file server application of our own design and implementation that is built with the CCNx C libraries; we use a standard CCNx utility for the client program. Our experimental setup is illustrated in figure 2.17.
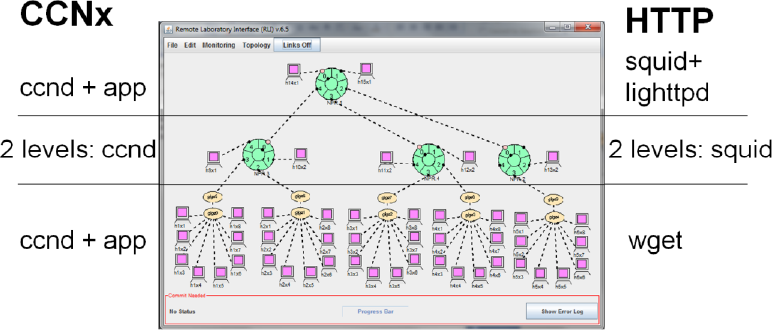
It should be noted that lighttpd and squid are much, much faster than CCNx at this point in time. This is expected given the amount of development these systems have enjoyed along the way to becoming operational platforms for some of the web’s most popular services. In fact, with respect to bandwidth, CCNx is typically around 10x slower. As a result, our CCNx experiments use 10MB files while our HTTP experiments use 100 MB files. Another caveat worth mentioning: while we practice sound experimental design, we are not yet fully exploring all factors that matter to us.
Our current experimental design consists of four primary factors, each with a range of values, as follows.
- File distribution architecture: CCNx or HTTP.
- Humber of clients: 1 to 40
- Levels in cache hierarchy: 1 or 2
- Prefilled caches: Yes or No.
In ongoing work, we are developing tools that generate workloads that can vary the distribution of name counts, lengths, and request patterns.
To get a feel for the optionally interactive nature of running NDN experiments in ONL, consider the real-time chart in figure 2.18.
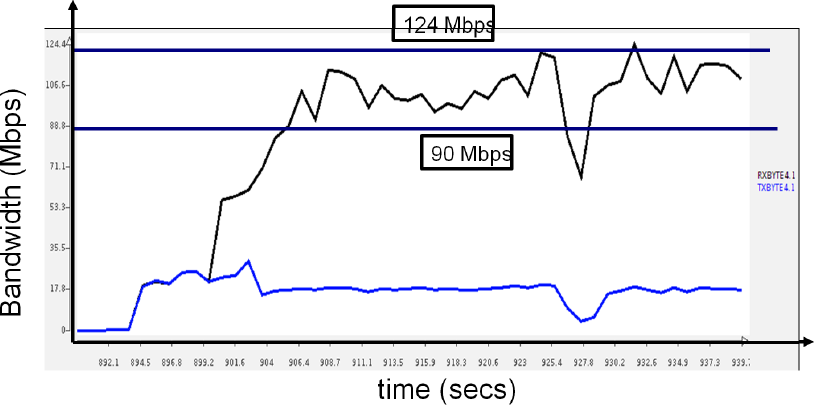
In this experiment, 8 CCNx clients request files from one other client that has already cached the files being requested. As can be seen, the sustained performance at this load is in the range of 90 Mbps to 120 Mbps. In fact, performance saturates at between 5 and 6 clients.
Ultimately, NDN forwarding will be limited by the rate of lookups and updates. To see where in the code CCNx spends most of its time, we profiled the system while under load. The results are in table 2.2.
| Function Name | Percentage (%) |
|---|---|
| ccn_skeleton_decode | 47.34 |
| ccn_buf_advance | 7.58 |
| ccn_compare_names | 6.1 |
| hashtb_hash | 5.87 |
| ccn_buf_match_dtag | 3.55 |
| ccn_pars_Signature | 3.11 |
| ccn_buf_match_blob | 2.01 |
| content_skiplist_findbefore | 1.48 |
| hashtb_seek | 1.36 |
| content_from_accession | 1.21 |
| The rest | 20.39 |
| Sum | 100 |
Table 2.2: GProf profile of CCNx under load
This profile was surprising. We expected lookups or updates to be the bottleneck, but we found that name decoding was, in fact, the culprit. Upon further investigation, we found that the CCNx code chooses to store cached names in the XML-encoded wire format, so that every lookup or comparison first requires decode. Hence, the decode function accounts for nearly 50% of execution time.
Our conceptually simple change was to alter CCNx to store decoded names. As we will see, this led to a doubling of throughput under these experimental conditions. The results can be seen in figure 2.19.
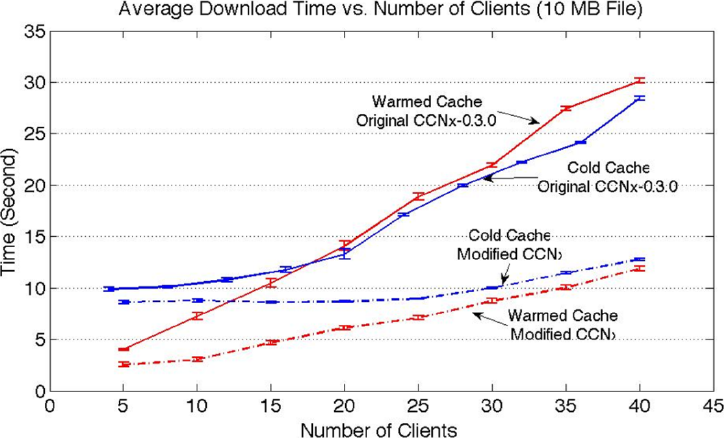
This reports experiments with just a single level in the hierarchy; all CCNx clients send their requests to the same upstream CCNx node. The solid lines report the average download times for the original CCNx implementation; the dashed lines report the performance for our modified version.
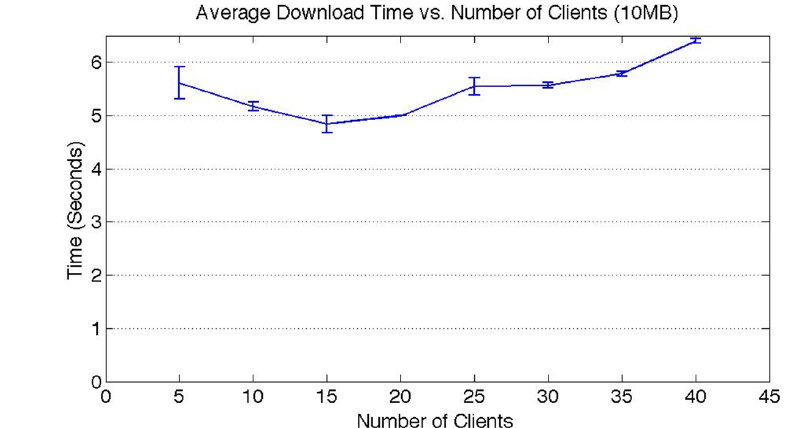
The figure 2.20 illustrates the scalability benefits when a 2-level hierarchy is used in CCNx. The file distribution time stays beneath around 6 seconds, regardless of the number of active clients.
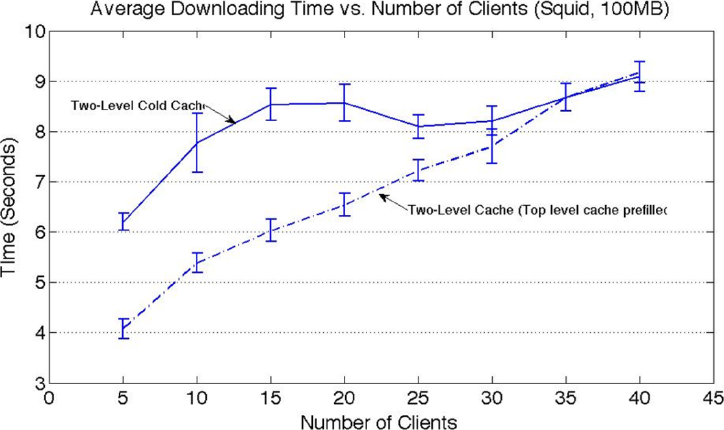
Results from HTTP experiments are shown in figure 2.21. These results (gathered with 100 MB files versus the 10 MB files for CCNx), illustrate the difference between a warm and cold top-level cache in a 2-level cache hierarchy. Overall the performance is superior, but the upward trend suggests an inferior scalability as compared to CCNx.
In summary, we find that under a reasonable set of experimental conditions, the original CCNx implementation sustains around 114 Mbps under load while our modified version sustains 246 Mbps. The lighttpd/squid HTTP caching system, on the other hand, sustains 865 Mbps under similar conditions.
2.4.4 Achieving Speed and Scale
The experiments described previously are based on a software-only implementation whose computation is expressed as a single thread of execution. In this project, we plan to achieve greater levels of performance through superior algorithm and data structure design, parallelization, and the use and design of hardware-based accelerators.
At this point, we consider it premature to discuss our early designs and analysis, but we feel confident in conveying that all current technologies are within the scope of our evaluation and design constraints, including multicore CPUs, TCAMs, NPUs, and logic and memory structures reduced to practice on FPGAs. In addition to prototyping with the above technologies, we expect to find justification to explore the design of new circuits and memory types, appropriate for ASIC fabrication, in support of NDN forwarding. Of course, we do not intend to fab any chips in the course of project, but we hope to explore designs for the core circuits of such chips.
Our highest-performance prototype platform is the Supercharged PlanetLab Platform, or SPP, which has been developed and deployed by our group as part of the NSF GENI initiative. The SPP platform consists of a chasis, with multiple line cards, each containing DRAM memory, and either CPUs or NPUs and a TCAM. The SPP supports 5 Gbps forwarding via a software-defined data plane, but the Internet2 links currently provisioned for use in GENI will only support 200 Mbps per link.
As an initial step, we have installed the NDN reference implementation to the 5 currently deployed SPP instances. Over time, as both the performance of our designs and the use of NDN within our project group increases, we expect the SPP nodes to play the role of a backbone network interconnecting the participating NDN project institutions. These are illustrated in figure 2.22.
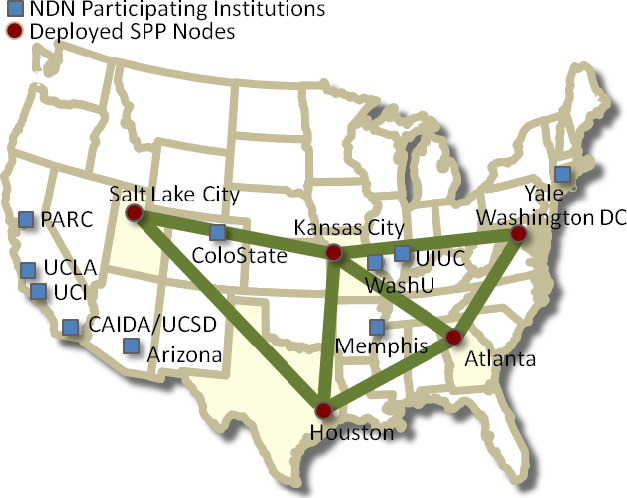
2.4.5 Related Work
- [53] M. Waldvogel, G. Varghese, J. Turner, and B. Plattner, “Scalable High Speed IP Routing Lookups”, in Proc. ACM SIGCOMM 1997.
- [52] S. Kumar and P. Crowley, “Segmented Hash: An Efficient Hash Table Implementation for High-Performance Networking Subsystems.” in Proc. of the ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), 2005.
- [48] J.S. Turner, Crowley, P., DeHart, J., Freestone, A., Heller, B., Kuhns, F., Kumar, S., Lockwood, J., Lu, J., Wilson, M., Wiseman, C., and Zar, D., “Supercharging PlanetLab: A High Performance, Multi-Application, Overlay Network Platform,” In Proc. ACM SIGCOMM 2007.
- [14] C. Wiseman, et al., Ä Remotely Accessible Network Processor-Based Router for Network Experimentation,” in Proc. of ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), 2008.
- [55] A. J. McAuley and P. Francis, “Fast Routing Table Lookup Using CAMs”, in Proc. INFOCOM 1993.
- [30] Francis Zane, Girija Narlikar, and Anindya Basu, “CoolCAMs: Power-Efficient TCAMs for Forwarding Engines”, in Proc. INFOCOM 2003.
- [22] S. Dharmapurikar, P. Krishnamurthy, and D. E. Taylor, “Longest prefix matching using Bloom filters,” in Proc. ACM SIGCOMM 2003.
2.4.6 Publications
The research results and activities described above have been disseminated via presentation at a conference, an NDN project retreat, and a GENI engineering conference.
- “Software-based implementations of updateable data structures for high-speed URL matching.” Haowei Yuan, Benjamin Wun, and Patrick Crowley. In Proceedings of the 6th ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS ’10), La Jolla, CA, October 2010.
-
“Using CCNx in the Open Network Lab.” Patrick Crowley. Presentation at the May 2011 NDN Project Retreat. PARC. Palo Alto, CA. May, 2011.
-
“NDN Forwarding Research.” Patrick Crowley. Presentation at the May 2011 NDN Project Retreat. PARC. Palo Alto, CA. May, 2011.
-
“SPP Deployment and NDN Research.” Patrick Crowley. Poster presented at the 11th GENI Engineering Conference (GEC 11). Denver, CO. July, 2011.
2.5 Security and Privacy
|
2.5.1 Objectives
Our primary objective is to design and implement efficient, user-/developer-friendly security mechanisms to support applications and routing components created (or yet to be created) in the project.
In contrast to today’s host based security model, a fundamental security primitive is embedded in the “thin waist” of NDN: the name in each NDN packet is bound to packet content with a signature. This fundamental feature provides data integrity and origin authentication, as well as a means to support trust and provenance by mapping between content and its source (e.g., an individual or an organization). On the other hand, generation, verification, transmission and storage of digital signatures incur overhead. Hence, one of our central goals is to streamline/minimize and carefully assess all associated costs by careful selection (and manipulation) of signature algorithms.
Naturally, privacy is a top concern for any Internet architecture. Basic NDN features contributing to privacy include lack of source and destination addresses in interest and content packets, and caching of content in the network. However, other features make privacy challenging, e.g., signatures of content reveal its origin, and names in content and interest packets reveal information about what content is flowing in a particular direction. One of our major goals is to develop a set of privacy techniques and tools to address such challenges and take advantage of privacy-friendly features of NDN. As described below, significant progress has been made towards this goal.
Another fundamental security feature of NDN is encryption-based access control, whereby content can be is encrypted, instead of synchronous communication pipes between hosts, as in today’s Internet (e.g., via IPSec). This allows encrypted content to be freely cached at, and fetched from, anywhere in the network. Named, signed and potentially encrypted content forms a solid foundation for routing (Section 2.2.2) security. However it also poses three major research challenges: cost-effective fine-grained security operations, functional and usable trust management, and protection of privacy. Some of our research activities during the first year of the project concentrated on these challenges as well as designing an overall attack-resilient routing/networking backbone for NDN.
2.5.2 Technical Approach
Efficient signing primitives
NDN’s core security model entails a digital signature in every packet on the Internet. Common wisdom suggests that this would be computationally expensive and, therefore, impractical. However, our preliminary results suggest that per-packet signatures for real-time data, such as voice, are in fact quite practical [46].
Simple techniques (e.g., Merkle Trees [56]) can be used to amortize signature generation and verification costs across multiple data segments in return for slightly higher bandwidth overhead. However, a key part of our research agenda is the need to design and implement signature techniques that are both computation- and bandwidth-efficient (ideally, at wire rate). Along with the usual cryptographic quest for new and more efficient signature schemes, we intend to focus on novel signature aggregation techniques.
The cryptography research community has developed “aggregate signature schemes” among which the best-known is BGLS [11], based on bilinear maps over elliptic curves. Such schemes allow for either incremental or simultaneous folding of any number of signatures – signed by potentially different signers – into a single aggregate signature. Schemes that only permit incremental folding (one signature at a time) into an aggregate are called “sequential aggregate signature schemes”. Whereas, schemes that allow aggregation of signatures by the same signer are referred to as “condensed signature schemes”. Finally, “multi-signature schemes” are those where multiple signers sign the same message. In the near term, NDN is most likely to benefit from condensed signature schemes, for several reasons:
- They are more efficient than aggregate schemes. For example, condensed RSA scheme [61] involves t modular multiplications to condense (into one) t RSA signatures. Also, verification of a condensed RSA signature costs t hashes, t multiplications and one low-value exponentiation. Whereas, aggregate signatures, while saving space, do not significantly improve costs over verifying t individual signatures.
- Aggregate signatures are mainly built upon non-standard cryptographic techniques from algebraic geometry, such as bilinear maps over elliptic curves. While well-accepted in the cryptography research community such techniques are not widely used in practice due to their computational cost.
- It makes more sense for a given content publisher to combine signatures for multiple packets it produces than for multiple publishers to combine their packets.
Thus, it appears that condensed signature schemes represent a viable enhancement to per packet signatures; they also offer an alternative to amortization techniques such as Merkle trees. However, one important caveat is that a condensed signature cannot be verified without all of its component messages.
Another promising area is the so-called “batch verification schemes”, e.g., [1]. Such schemes aim to speed up (batch) the verification process given many signatures on different messages, usually generated by the same signer.3 Once again, RSA-derived batch schemes are particularly efficient [1], though schemes for DSA have also been proposed [41]. Since they assume that each message is accompanied by its individual signature, batch schemes may even more useful in NDN than condensed signature schemes.
In summary, we plan to and in the process of developing computation- and bandwidth-efficient signature schemes for NDN. We are applying work in fast signature schemes (e.g. [63]), techniques that allow semi-trusted proxies to sign on behalf of weak devices [24,25,23], as well as methods for aggregate signature generation and verification (from Merkle Hash Trees (MHTs) [56] to using bilinear maps over elliptic curves [11,61] and related batch verification schemes e.g. [1,41]). We will also investigate techniques for spreading signature meta-data over multiple packets. Although some of these schemes have not yet seen practical deployment, variants of them are promising for NDN and we determined to find/design/deploy them.
Content Protection
Integrity, provenance and trustworthiness of content are necessary but not sufficient; content publishers want fine-grained access restrictions on sensitive or valuable content. Since NDN consumers are likely to obtain desired content from caches rather than the original publisher, content protection cannot rely on entities (hosting caches) to enforce its access control policies. Therefore, similar to content-based data authenticity, NDN adopts the familiar content-based approach to access control, obtained primarily via content encryption. Encryption is end-to-end and largely opaque to the network layer, handled by applications or libraries. Most schemes for protecting content by encryption (e.g. broadcast encryption [29,49,62,12] and encryption-based access control schemes [3,8,4]) can be adapted to NDN by choosing appropriate naming schemes and data representations for keys. We are in the process of selecting and implementing appropriate schemes for specific applications (Section 2.1), prioritizing efficiency and compatible support for revocation. We will also examine content firewalls within the next year(s) of the project, whose atomic unit of protection is content referenced by name to provide a method of user-friendly perimeter control for restricted content.
Privacy
Lack of privacy in digital world becoming an increasing concern among users. Consumers want to maintain their privacy by not exposing information about content they retrieve over the internet. Although an NDN interest refers to a potentially human-readable name, NDN implicitly offers better end-to-end privacy than IP since it only tracks what data is being requested and not who is requesting it (Section ). However, NDN poses three important privacy challenges: (1) Cache privacy, because as with current web proxies, network neighbors may learn about each others’ content accesses using timing information to identify cache hits; (2) Name privacy, since the more meaningful NDN content names are, the more sensitive they may be; and (3) Signature privacy, because the identity of a content signer and its revocation status may leak sensitive information about individuals and organizations.
Various methods of addressing these challenges, e.g., VPN-like tunnels or in-network support for encrypted name components for Name Privacy, offer different trade-offs between privacy and cacheability. We can only scratch the surface of the privacy models possible in the NDN architecture, but to explore the limits of attainable privacy, we design and implement a flexible name encryption scheme as well as the NDN analogs to Tor [26] to maximize data path diversity and cache dispersal.
We also plan to explore practical applications of group signature schemes [17,5,15,74,10,13] for signature privacy, where any member of a group can sign on behalf of the group, and anyone can verify a group signature, but the identity of the signer remains private and no connection can be made between multiple group signatures. We need to explore obtaining at least some of the appealing features of group signatures at acceptable (i.e., lower) costs. (This might require deconstructing group signature schemes to come up with derivatives offering somewhat weaker privacy properties but at lower cost). Group signatures can also be used in combination with ephemeral keys, where “expensive” group signatures are used to delegate trust to ephemeral keys used to sign content.
Network Security and Defense
Any future Internet architecture must offer improved protection and resilience over today’s network, which is subject to pervasive and persistent attacks. NDN network security is based on the establishment of a trustworthy routing mesh, relying on signed routing messages and an appropriate trust model unlike today’s Internet. NDN’s architectural features e.g., native support for multipath routing, continuously observable in-network route feedback by interest induced states on routers, facilitate a level of attack resistance exceeding that of IP. Moreover, NDN packets address content instead of end-points, making it difficult to target a particular host, and the fact that NDN nodes forward data only in response to an incoming interest makes it impossible to flood unsolicited data through an NDN network.
The research challenges for NDN network security are 1) designing a trust model to defend against attacks on the routing mesh while supporting common providers’ practices and policies, and 2) designing defenses against new types of attacks. We have designed a trust model appropriate to each of our routing research approaches (Section 2.2), and plan to implement and further evaluate it in experimental deployments. We will address Interest Flooding Attacks (mirroring traditional denial of service (DoS) attacks) which send large numbers of new and distinct interests that cannot be aggregated or satisfied from caches, and Content Pollution Attacks which introduce malicious content purporting to match legitimate requests. For Interest Flooding Attacks, we plan to conduct experiments with routers that throttle the number of unsatisfied interests they will hold for a given target domain. For Content Pollution Attacks, the consumer should always use signature verification to reject malicious content, but we also plan to evaluate the burden of ingress filtering and egress filtering in (non-core) routers to protect against simulated attacks. We recognize other possible attacks, such as “hiding” content from legitimate requesters and abusing cryptographic operations to mount DoS attacks, which we hope to identify and investigate in the later years of the project.
Trust Management
Signature verification of NDN content merely indicates that it was signed with a particular key. Making this information useful to applications requires managing trust – allowing content consumers to determine acceptable signature keys in a given context.
NDN provides an excellent platform for deploying both accepted and new trust management models. Keys can be treated as named NDN data and signed NDN data items effectively function as certificates. NDN can express secure links between pieces of content, allowing certification of not only keys, but of content itself. This provides a rich substrate where many pieces of linked “evidence” can support consumer trust in a particular piece of content. For example, a consumer might verify the front page of the New York Times because it is signed with a well-known certified key. She can then verify individual articles because the front page links securely to them. One advantage of NDN is that it does not require a “one size fits all” trust model: trust is end-to-end, between producer and consumer. Different consumers and different content may require varying levels of assurance. However, to make NDN accessible and deployable, it must come “out of the box” with a set of usable trust mechanisms applicable to a wide range of applications.
Prior research in trust management for large-scale deployment of public key cryptography has resulted in two main approaches: hierarchical Public Key Infrastructure (PKI) [19], and peer-level PGP web of trust [80], both with significant usability problems [39,78]. Recent research shows that these approaches can be made more user-friendly [40,6] and constructs new ways for automatically developing trust in keys through observation and experience [38,65,77]. One model of particular relevance to NDN is SDSI/SPKI [70,28,2], which maps a small-world model of trust onto a notion of local “namespaces” for naming keys, which in turn can map directly into the NDN notion of content namespaces. We will experiment with such models and evaluate them in the context of the applications and routing work.
We also plan to design solutions for revocation, the problem of deciding when a key (or credential) can no longer be trusted, which is particularly acute in NDN due to caching. Faced with signed content that may have been cached for a while, we need to determine whether the corresponding key (1) has been revoked, and (2) was valid at the time of signing. Although current revocation approaches (CRLs, OCSP [60]) can be used with NDN, they will likely be even less effective than in more traditional contexts.
2.5.3 Progress During the First Year
A major focus of the NDN project is integrating security into the thin waist of the communication network architecture. In the first year of the project, we worked closely with application and routing research teams to assess the usability and suitability of the NDN security architecture for their needs. The basic premise of the NDN security team is the application-driven approach: security design evolves based on application requirements and feedback from NDN application developers.
During the first year, we confirmed the validity of basic assumptions about NDN security. Notably, in terms of security, NDN offers significantly more than IP. Each NDN content chunk comes with a name and a signature, which benefits both functionality and security: a name gives context and a signature provides secure provenance for content. These features free application developers from the burden of dealing with them at higher levels, in contrast with IP. Some examples of applications benefitting from these features can be found in Section 2.1. For example, architectural lighting or participatory sensing applications are hard to secure in IP networks, whereas, NDN makes securing them both easy and natural. The NDN routing model (see Section 2.2) shows that network infrastructure is not an exception – routing can be seen as just another application over NDN – and it is easy to secure it as well.
Name Privacy and Anonymous Communication: NDN routes and forwards packets based solely on names. NDN names are opaque to the network, i.e., routers do not know the meaning of a name, only the boundaries between name components. This allows each application to choose the naming scheme that best fits its needs. As a consequence, applications and users are incentivized to choose names that are semantically related to specific content. Since NDN does not conceal content names by default, some concern over name privacy has arisen. This motivated us to explore mechanisms to conceal entire (or parts of) names via encryption. We have considered approaches ranging from architectural support for routable encrypted names to service-level solutions, such as the NDN analog of onion routing.
Our results showed that, unlike IP, even base NDN provides some basic anonymity for content consumers, since interests do not carry source addresses. We started exploring techniques for routable encrypted names to provide stronger privacy properties and introduce a basic form of censorship resistance. To that end, we designed and implemented an efficient protocol that supports name en/de-cryption on select NDN routers. In this design (Figure 2.23), user applications encrypt names (in interests) such that, even without information about the network topology, their distance from the content (in terms of hops) is comparable to the same distance when using unencrypted names.

Subsequently, we designed and implemented an anonymization service based on onion routing. Similar to onion routing based anonymization services that run over TCP/IP, our service is implemented at the application layer without requiring any architectural level support. The resulting system can be thought as the NDN analog of Tor, where interest packets are concentrically encrypted for a number of anonymizing nodes and content satisfying that interest is again concentrically encrypted using requester-provided keys on its way back. Since both interest and content packets are encrypted concentrically (encryption layers on top of each other), this design provides strong anonymity, unlinkability and censorship resistance. While designing this solution, we relied on and utilized some fundamental properties of NDN. For example, our approach requires only 2 anonymizer nodes for a comparable privacy guarantees that could be achieved only with 3 or more anonymizer nodes over IP. Moreover, our approach does not need initial communication circuit creation: it can utilize dynamic and multipath anonymization routes for better performance and privacy, which are all atypical to systems running over IP. Moreover, even our preliminary, i.e., non-optimized, implementation has introduced acceptable delays and communication overload over base NDN in our tests. You can see the effect of using 2 anonymizer nodes on round-trip and the total download time in comparison to regular NDN in Figure 2.24.
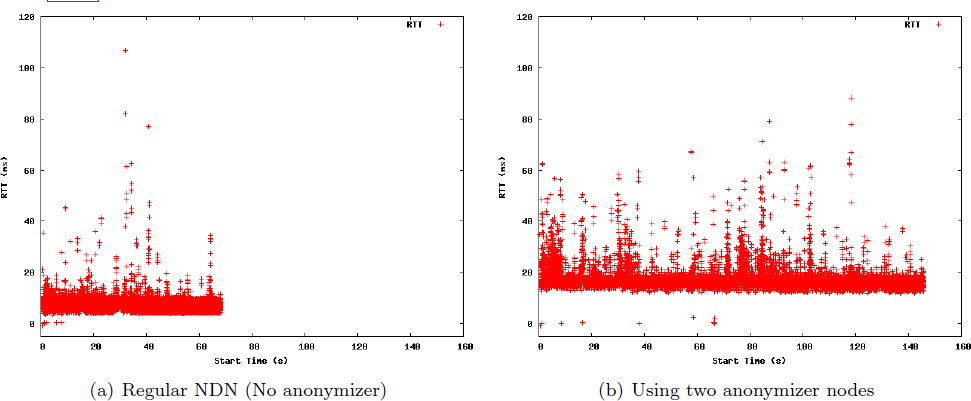
Efficient Security Operations: Efficiency of security operations, especially signature generation/verification, is a crucial requirement for NDN. During the first year of the project, we surveyed numerous signature schemes and techniques to speed-up their verification. We have also conducted empirical studies (e.g., see Tables 2.3 and2.4) to see their performance under different conditions. In particular, we evaluated the performance of online-offline signatures, summarized in Table 2.5, since they can be efficiently implemented in low powered devices.
| 1024-bit (equivalent) | 2048-bit (equivalent) | |||||
| Sign | Verify | Sig. Size | Sign | Verify | Sig. Size | |
| RSA-PKCS#1 | 1.764ms | 0.084ms | 1024 bits | 10.425ms | 0.282ms | 2048 bits |
| Rabin-PRab | 2.238ms | 0.013ms | 1024 bits | 11.269ms | 0.032ms | 2048 bits |
| DSA | 0.855ms | 1.008ms | 320 bits | 2.774ms | 3.285ms | 448 bits |
| ECDSA | 0.205ms | 0.926ms | 320 bits | 0.315ms | 1.542ms | 448 bits |
| 1024-bit (equivalent) | 2048-bit (equivalent) | |||||
| Sign | Verify | Sig. Size | Sign | Verify | Sig. Size | |
| RSA-PKCS#1 | 26.4 ms | 1.3 ms | 1024 bits | 159.8 ms | 4.4 ms | 2048 bits |
| Rabin-PRab | 29.7 ms | 0.18 ms | 1024 bits | 162.5 ms | 0.42 ms | 2048 bits |
| DSA | 12.9 ms | 15.2 ms | 320 bits | 43.5 ms | 51.1 ms | 448 bits |
| 1024-bit (equivalent) | |||
| Offline(ms) | Online(ms) | Verify(ms) | Sig. Size |
| 8.115 | 0.002 | 10.849 | 1024 bits |
Usable and efficient encryption based access control is another requirement for NDN. Current NDN source base is already equipped with a group-based access control scheme that can support basic access rights e.g., read, write, manage, over dynamic groups and we continue to work on enriching the access control schemes that will be available to NDN application developers.
Routing Security: During the first year of the project, we extensively collaborated with the routing group to design and develop a routing security and trust model. Please refer to Section 2.2 for the details of our progress and next steps.
Secure Sensor Networks and SCADA Framework: In an effort to supply necessary tools for secure application development over NDN, we developed an application framework to support the development of secure sensor networks and industrial automation applications. Our framework implements some fundamental functionalities on top of NDN that provide authentication and confidentiality of names. In particular, we developed a secure one-round protocol for interest authentication and a secure encryption protocol for information embedded in names. Both our protocols are particularly efficient and have been successfully tested in applications running on low power embedded devices. These protocols have been specifically designed for some of the applications introduced in Section 2.1. In particular, our framework provide a complete toolset for implementing the basic communication primitives of the personal data cloud (PDC) and the nodes in the media-rich instrumented environments.
References
2.5.4 Publications and Presentations
- Steven Dibenedetto, Paolo Gasti, Gene Tsudik, Ersin Uzun; Privacy in Named Data Networks, Conference Paper under submission, 2011.
- Paolo Gasti, Yanbin Lu; Preliminary evaluation of various signature schemes for NDN, UCI Technical Report, 2011.
- Paolo Gasti, Yanbin Lu, Gene Tsudik, Ersin Uzun; Encrypted names in NDN, UCI Tech Report, 2011.
- Van Jacobson, Diana Smetters; Securing Network Content, PARC Technical Report, 2010.
- Gene Tsudik: NDN-focused keynote/invited talk titled: “Some Security Topics with Possible Applications for Pairing-Based Cryptography” at the International Conference on Pairing-Based Cryptography (PAIRING), Yamanaka, Japan, December 2010.
- Gene Tsudik: project presentation on NDN security at the NSF FIA PI meeting in Oakland, CA, May 2011.
2.6 Network Management and Monitoring
|
2.6.1 Objectives
Today’s network management focuses on managing “who” can communicate. Sources and sinks of data are identified with IP addresses or IP prefixes, and ISP routing policies (i.e. customer, provider, and peering relationships) determine who can communicate over particular paths. An ISP announces routes to its customers’ IP address space to everyone, but typically do not announce routes learned from peers to other peers. NDN changes the fundamental unit of transport from IP addresses to named content, which implies a paradigmatic change to network management: it no longer matters “who” (which IP address) is communicating, but rather what content is transferred. We are investigating two operational research questions in scalable management and monitoring of NDN networks: peering policy configuration management, and traffic monitoring and engineering.
2.6.2 Technical Approach
Peering Policy Management
Expressing and configuring policies based on names rather than addresses allows more human-friendly, and thus realistically scalable, network management, supporting policy configuration in terms of collections of data that naturally correspond to network traffic exchanged between customers, providers, and peers. In an IP model, an ISP A announces Customer B’s IP address space. In NDN, ISP A provides reachability to Customer B’s content, implying an economic incentive to make that content available to anyone seeking it. Upon receiving an expression of interest for Customer B’s content, ISP A will forward the Interest to Customer B and relay the resulting content back toward the requestor, but also cache the content so future requests can be served directly by the ISP. Similarly, when Customer B expresses an Interest in some content, ISP A has an economic incentive to obtain it, and cache it internally if it is requested often (by B or another customer).
NDN networks also support the equivalent of today’s peering relationships. Suppose ISP A has peers ISP X and ISP Y. ISP A would like to provide its own customers with access to content generated by customers of ISP X and Y, but lacks economic incentive to ensure that customers of ISP X can access content generated by customers of ISP Y. In an IP policy management model, ISP A would limit which IP addresses it announces where. NDN achieves a similar goal by not forwarding expressions of interest and/or not relaying data. We believe that policy semantics based on content better match the customer goals, which are typically focused on which content the customer wants to be able to reach rather than which IP addresses are accessible. We will extend our topology and routing visualization tools to support annotations based on named content and organizational boundaries.
Traffic Monitoring and Engineering
Once a policy is implemented, network operators must monitor whether the system is working as expected. If an ISP configures policy to allow customer access to particular content, the ISP must ensure that this content is reachable despite failures, misconfigurations, or attacks. Reachability benefits greatly from the inherent redundancy in the architecture, where many paths may reach (because many caches may serve) a particular named content item. This redundancy is similar in spirit to the astoundingly effective redundancy inherent in the current DNS architecture; well-managed DNS zones operate multiple distributed name servers, any of which may respond to resolver requests. But, like the DNS, the redundancy can also mask reachability problems, since only one server may be responding to requests while all other servers are unreachable. Furthermore, a network provider may want to balance traffic load along certain links rather than others, which requires visibility into traffic flow similar to that provided by today’s traffic measurement tools. Leveraging our previous work on Internet routing and traffic monitoring, we will build monitoring and reporting systems that provide data owners or providers with a view of where data is cached and what failures may disrupt access to the data, enabling real-time evaluation of and adaptation to system resilience issues in a way not possible with the current architecture.
Consequently, a network can influence others’ decisions by handling the Interests received from different neighbors differently. For example, if it intends one provider to be a backup, it may simply drop the Interests received from that provider or assign them a lower priority. Finally, NDN networks will have business considerations analogous to those that hold today, e.g. mutual agreements on the maximum prefix length allowed across a peering session.
There is an important distinction between the degree of resilience experienced by the user and the degree of resilience intended by the system operator [68]. Suppose for example that a data owner believes some particular content is widely distributed throughout the NDN network. To the user, the system works as long as one copy of the data is obtainable and so an error will be reported only if access to all copies fails. For popular data that is widely distributed, one might expect that the loss of all copies is unlikely. The user perceived robustness is very high. From a system perspective, however, the lack of user complaints may mask fundamental underlying problems. The data owner may believe that there are multiple copies of the content scattered throughout the network, but in fact only one copy may be reachable. If that copy fails for some reason, the content suddenly becomes unreachable. The current DNS provides well known examples of this, where the DNS zone owner believed multiple copies existed only to discover that all copies of the data were behind a single switch or dependent on a single router [68]. The network monitoring tools and services that we are building should provide a content owner with more visibility.
NDN can adapt to potential failures by pushing data to key locations in the network. The potential for content to reside at multiple locations provides new opportunities to adapt in the face of both attacks and failures.
2.6.3 Progress
| Component | Name | Controls | Setting | Description |
|---|---|---|---|---|
| Routing Plane | Routing/BIB | Routes | Not Selected | Route cannot be used to forward Interest packets. |
| Selected | Route may be used for forwarding Interest packets. | |||
| Select and Announce | Route may be used for forwarding Interest packets and may be announced to peer groups. | |||
| Content Store | Cache Access | Interests | Allow | Check Interest against cache and proceed to PIT if no matches are found. |
| Cache Only | Check Interest against cache and drop if no matches are found. | |||
| Deny | Drop Interest without checking cache. | |||
| FIB | FIB Usage | Full Usage | New matching faces may be found and added to the existing face list. | |
| Limited Usage | No new faces may be added to the existing face list. |
Table 2.6: Examples of NDN policy knobs (not exhaustive).
Table 2.6 provides an overview of the policy knobs available to NDN network operators. As with BGP, there are routing plane knobs; but in addition, NDN offers several data plane knobs. These operate on components that are new or modified in NDN, such as the content store (CS), the Pending Interest Table (PIT) and the Forwarding Information Base (FIB). Note that the FIB in NDN has some significant differences from the FIB in BGP: in NDN the FIB is used to forward Interest packets only, and may contain multiple entries for the same name prefix. Data packets follow the reverse path marked by PIT entries back to get back to the originator of an Interest packet.
Routing Plane Knobs: In the current Internet, AS policies are implemented by the BGP routing control plane [34] and a number of prefix attributes. BGP selects asingle best route to a prefix, which may then be exported to a select set of neighbors. While similar knobs are available in NDN, there are a couple of important differences. First, route selection in NDN influences forwarding of Interest packets, not data. Data packets follow the state left in the PIT by Interest packets, so packet flow is symmetric. Note that this is in stark contrast to the current Internet, where packet flow is often asymmetric. The second difference is that NDN can selectmultiple feasible interfaces in an attempt to find content nearby.4
The table shows the possible settings of the route selection knob at the routing plane. An advertised route (or name prefix) can be ignored, selected, or selected and propagated to neighbors. Furthermore, NDN may maintain multiple routes to a given content collection. Which routes to use when searching for the content is determined by FIB policies, which are described below.
Content Store: The Content Store (CS) acts as a cache for an NDN router and adds a new set of policy knobs at the data plane, which are not present in the current Internet. The CS Access knobs are shown in Table 2.6) and provide the operator an opportunity to determine whether or not an incoming Interest packet is allowed to access cached content. The first setting Allow determines if an arriving Interest packet is allowed to search the CS for the desired content. An Interest may be denied access to CS if, for example, the Interest came from a peer and there is no agreement to allow the peer unfettered access to the CS.
Forwarding Information Base: The routing plane in both BGP and NDN utilize a routing information base (RIB) to record available routes. BGP will select a single, best route for each prefix from the RIB and install it into a forwarding information base (FIB), typically on the router’s line card. The data plane decision is simple. If a FIB entry exists, it indicates which interface will be used to forward a matching IP packet.
NDN allows for multi-path routing and thus multiple faces can be associated with a FIB entry. The routing plane only determines which faces could be used by the data plane to forward an Interest packet. The data plane’s face selection may be controlled through the FIB Usage knob. For example, Interest packets from a customer may be forwarded over all possible faces selected by the routing plane policy. However, an Interest packet (for the same name) from a settlement-free peer may only be forwarded over a subset of the possible faces.
Data Packet Policies: Note our knobs have focused on policies for Interest packets. Data packets follow the trail left by Interest packets and will be processed only if there is a matching PIT entry. Undesired Data packets are blocked preemptively by not forwarding Interest packets. Conversely, if a node created a PIT entry and forwarded an Interest packet, it is expected to also relay the corresponding Data packet. As such, the only policy-related question for a Data packet is whether to cache the content. Caching strategies are an interesting challenge of future work.
2.6.4 Related Work
Network management lies at the intersection of technical challenges and economic interests. Huston [44] first examined the delicate balance between competitiveness and cooperation ISPs face in order to exist as a business. The author investigates a range of settlement models and business relationships between ISPs. Our work is in a similar spirit as we explore the underlying economic incentives and new possible business relationships that could occur in an information-centric network.
Our work is similar in spirit to that of Rajahalme et. al [69]. The authors are perhaps the first to analyze the economic incentives, or lack thereof, for tier-1 ISPs to deploy information-centric network architectures. Furthermore, the authors also explore novel data-centric policies that may develop. While Rajahalme et. al analyze several different ICN architectures, our work obviously focuses on the NDN approach [45] and how its specific features lead to interesting inter-domain routing policies. Additionally, we study ICN policies from the post-deployment perspective in order to focus on the full potential of these novel architectures.
Gao [31], which is widely regarded as the seminal work on routing policy inference techniques for today’s Internet, was the first to use economic incentives and Huston’s peering suggestions to infer AS relationships. Using this approach, an AS-level topology can be annotated with business relationships according to observed routes, the valley-free rule, and node degree. Our work uses Gao’s business relationships and the valley-free rule as a starting point to explore possible NDN policies.
References
2.6.5 Publications
- Steve Dibenedetto, Christos Papadopoulos, Daniel Massey, “Routing Policies in Named Data Networking”.
SIGCOMM 2011 Workshop on Information Centric Networking, August 2011
2.7 Evaluation and Assessment
|
2.7.1 Objectives
The ability to experiment, measure, modify, and re-design is an essential part of building any future Internet infrastructure. Any design involves trade-offs and an ability to assess these trade-offs is essential. One can make some estimates on whiteboards and run simple simulations, but we believe nothing compares with running code. In addition to the expected analysis of design trade-offs, running code provides additional unexpected benefits. Components will interact in unexpected ways, software will be misused, network operators and users will not behave as expected. One can only learn some lessons by actually trying the experiment, and the experiment may not go as planned. Thus a key objective for the Evaluation and Assessment team is to provide running platforms where all the designs from routing to security to applications can operate. These platforms allow us to assess NDN’s ability to support existing and new applications, as well as its performance, scalability, and robustness.
2.7.2 Technical Approach
We use NDN-connected testbeds, simulations, and theoretical analysis to identify problems in the design and evaluate performance at different scales. Table 2.7summarizes the key metrics and evaluation methods for each project area.
| Evaluation | Key Metrics | Method |
| Routing and Data Delivery | FIB size, PIT size and lifetime, routing & Interest message overhead, successful path probability and length distribution, delay in finding data, optimal number and diversity of paths, | T, S, A |
| Hardware | FIB update delay, packet processing delay (including lookup delay) | T |
| Caching | cache size, hit ratio as a function of content type | T, S |
| Flow Control | interface throughput, link utilization | T, S |
| Application support | ease of creating applications (e.g. closeness of mapping between application needs and network support [33]), application-level data throughput | T |
| Privacy | privacy preservation capability of NDN analog of TOR | T |
| Data security | speed of generating and verifying signatures | T |
| DDoS | percentage of requested data delivered to legitimate users | T, S |
| Capacity and Traffic | total amount of information transported by the network in space and time (i.e. consumed entropy rate), traffic patterns compared with IP | T, A |
1. Testbed Infrastructure for Running Code
Besides an overlay testbed network composed of NDN nodes, we use the Open Network Lab (ONL) [64], GENI Supercharged PlanetLab (SPP) [75,32] nodes on Internet2, and a PlanetLab-Like Platform (PLP) for evaluation. Each of these testbeds is discussed briefly below.
NDN Overlay Testbed We have set up an overlay testbed that supports NDN connectivity over the public Internet among the project sites (see Figure 2.25). This NDN testbed is used both as a collaboration tool and as an experimental platform for the running code. Active, regular use can teach us about the evolving architecture and spur rapid progress of prototypes.
Open Network Lab (ONL) We are using the NSF-funded Open Network Lab (ONL) at Washington University as an instrumented testbed, particularly well suited for fine-grain measurement studies on platform performance as well as for experiments with forwarding decision designs. Currently the ONL testbed runs the software-only version of the NDN prototype on programmable routers, and has already proven to be an effective resource as presented in more detail earlier in Section 2.4.
Supercharged PlanetLab Platform (SPP) As described in Section 2.4.4, the Supercharged PlanetLab Platform, or SPP, is a high-performance hardware prototype platform developed and deployed by Washington University as part of the NSF GENI initiative. Five SPP nodes with NDN reference implementation are currently deployed on Internet2 and more nodes will be added. We expect that an overlay network among the SPP nodes may play the role of a backbone to provide high speed interconnection among the participating NDN project institutions.
PlanetLab-Like Platform (PLP) Some application studies benefit from a high degree of control on the end nodes, or need to run topologically-sensitive experiments. In these cases, the primary overlay testbed may not be sufficient since it has natural administrative boundaries and is needed by the entire team. For example, consider the problem of running a routing protocol test. In testing the routing protocol, one would clearly like to run software at multiple sites. However, sites are using the overlay testbed for conferencing and other experiments and owners naturally want to limit root level access to their testbed boxes. We are exploring a PlanetLab-Like Platform (PLP) where some boxes at each site are assigned to the PLP. Any user has access to the servers, can launch virtual machines, and can configure their own topology by creating tunnels between boxes at each site.
2. Simulation and Theoretical Analysis
We have chosen ns-3 as a simulation platform for NDN and started the development effort of an NDN simulation platform that can be used by both our project team as well as the boarder community to investigate various system properties of NDN. Our simulations will use the best available data on Internet behavior, traffic data from the DHS PREDICT project, AS-level topology derived from RouteViews data [73] and annotated router-level topology data from CAIDA. Theoretical analysis will allow us to cross-validate against simulation experimental results, e.g., regarding topology structure and network capacity.
3. Monitoring and Measurement
Network Operations Center (NOC) We expect our testbed links (tunnels) to fail, machines to crash, performance to be less than what is necessary, and unexpected changes to occur frequently. Therefore, we are matching the NDN testbed with a Network Operations Center (NOC) for monitoring and management, which gives us an early path to explore network management in general for this new architecture.
Instrumentation Comprehensive evaluation of the NDN architecture requires instrumentation that facilitates macroscopic performance evaluation, including software support for measurement of metrics in the first five lines of Table 2.7. We are instrumenting NDN to support and leverage collection of data about faults, while respecting legitimate privacy concerns. This will provide incentives to gather and share measurements.
4. Security Testing
To evaluate the privacy preservation capability supported by NDN, we are implementing an NDN analog of TOR [27]. Using the published known vulnerabilities of TOR [66], we will emulate the same attacks on our solution. For broader security evaluation, we will build on our experience with penetration testing games [18] to host “red team” competitions where groups not involved in NDN design attempt attacks against participating NDN testbeds. We will emulate and evaluate the impact of different types of Denial of Service attacks using both simulations and testbeds.
2.7.3 Progress
A major focus of our attention early in the NDN project has been on the launch of the NDN testbed network described above. At this stage it is still too early in the research to have made major progress on evaluation.
Basic Connectivity
We launched our efforts to establish an overlay NDN testbed with a Testbed Day in January 2011. During this event, all project sites (with exception of two that had local resource limitations) established links to form the testbed. The resulting topology is shown in Figure 2.25. The basic design has a hub at each site. The hubs use tunnels over the public Internet to create our backbone links. For example, the figure shows the hub at Colorado State connecting to hubs at PARC, CAIDA, Arizona, Memphis, and WashU. Within a local site, both dedicated servers and student laptops connect to the hub. This allows a student laptop at UCLA to communicate with a student laptop at Memphis. We tested connectivity between all the sites using ccnchat, a simple text chat application, and the student operators at all sites were able to join the chat and exchange relevant configuration information.
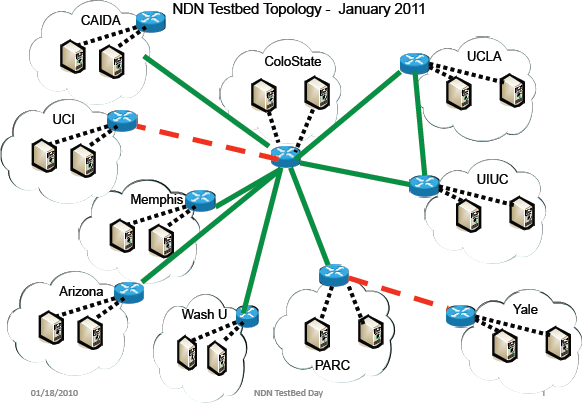
The operator team developed a set of instructions both for configuring a hub and configuring an edge system. All the instructions are posted on the www.named-data.net website and will evolve as the testbed grows and develops during the project. So far the testbed provides only very basic NDN connectivity, using statically configured forwarding tables. Adding dynamic routing is one of the key next steps in the project and this work has already begun.
Although this overlay testbed already provides us with some basic NDN connectivity, we emphasize the word basic. Besides the lack of a functioning routing protocol to propagate the reachability of data names, network naming is among the first challenges we encountered in setting up and managing this overlay testbed, as expected. We currently have a simple naming system that allows both `broadcast’ and site-specific names. Developing a set of guidelines on network naming is a key next step. There are two fundamental naming problems. First, one needs a name for a box itself. In the Internet, IP addresses have often been misused in network management and measurement. For example, one can identify a router by its IP address. However, the router has multiple IP addresses and the resulting challenge has been identifying that two IP addresses actually belong to the same physical router. In NDN, we want to start with a unique node name rather than an interface name. A draft node naming convention has been proposed and is now being implemented in the testbed.
Second, one needs to be able to address a class of devices. For example, a management agent may need to gather data from all routers or all firewalls inside the organization. As discussed earlier in Section , the owner of the management agent is important. It is perfectly valid for the Colorado State security management agent to obtain data from all Colorado State firewalls. It is not valid for the Colorado State security management agent to obtain data from all PARC firewalls. We are exploring whether this group communication is best accomplished via directed queries or group routes.
Network Operations Center (NOC)
A NOC is essential to addressing problems on network management and operations. This is not an optional feature of a Future Internet Architecture; without network management and operations, any architecture is doomed to be a purely academic exercise with limited value. The theme of NDN is to focus on what data the user seeks, not where the data is located. In other words, the user is satisfied if the correct data is obtained; the actual node that supplied the data is irrelevant to the user. Does this fundamentally new architecture need a new type of network operation center? Should network operators and network users both care about the same types of information? For example, a network operator may need to know that the link between node N and node M is down in order to maintain and troubleshoot the network, while a network user on the other hand requests data by name and does not care (and does not even know) which particular node served the data. The user is not exposed to node N or M or their link. In a first year network course at Colorado State, the graduate students were asked to build NDN NOCs with the above issues in mind. They produced a variety of designs tracking items from the NDN PIT to NDN Interest routes. These results offer an initial input into the design of an effective NDN management system.
The students were first required to install a 5 ∼ 10 node NDN testbed, using PlanetLab to get a diverse set of machines, and to use ccnchat to demonstrate basic connectivity. The students were provided with the guidelines developed in NDN Testbed day and all students were able to successfully establish their own testbed. A basic goal for the NOC was to provide an automated picture of the topology. Here the students developed NDN applications that exchanged Interest and Data packets to learn the topology. Most designs were simple variations of OSPF (link state) implemented using NDN Interest and Data packets. Having the basic topology is useful, but we also want to identify links by standard network measurements such as delay, bandwidth, congestion on the link, and so forth. Computing these basic performance metrics required NDN features such as name scoping to force probing packets to go through specific links. The project teams used a combination of scoped messages and clever manipulation of routing to ensure a round-trip time (RTT) measurement did indeed follow the intended links to go to the correct nodes.
Figure 2.26 shows one of the designs. The topology shown in the figure updates dynamically as nodes/links are added or deleted. The performance measurements such as RTT are also updated automatically. Some of the options allow one to display the path that Interest packets would follow from a particular node to a given content name.
As a result of this work, we have developed a broader node naming convention that spans network management and other functions such as routing. Using a well defined node name, we have borrowed the concept of a MIB (management Information Base) from IP management and developed an initial NDN MIB and a Java based management agent. At one level, we have built an NDN system for obtaining management and measurement data (RTT, Bandwidth, Topology). More fundamentally, the agent design and implementation provides a framework for building management features, e.g. adding new measurements such as jitter, or adding in disclosure control and support for network management policy. This is discussed further under Next Steps in Section below.
Open Network Lab (ONL)
Progress in using ONL and GENI SPP is covered earlier in Section 2.4.
PlanetLab-Like Platform (PLP)
This work is in the early stages. Several experiments have been run on the existing PlanetLab infrastructure. We are exploring the use of open source PlanetLab software to create and run our own PlanetLab-Like Platform.
2.7.4 Related Work
There is considerable related work on operations and management for IP networks; notably entire conferences such as the Network Operations and Management Symposium (NOMS) explore management topics. We are currently looking at how an information centric design changes network operations. Our approach is both theoretical analysis and experimentation through building and operating a NOC.
2.7.5 Publications
There are several web publications on how to install and operate various aspects of the testbed, all linked from http://www.named-data.net, but no conference publications at this early stage.
2.8 Fundamental theory for NDN
|
2.8.1 Objectives
Information theory [72] provided the architectural basis for both the digital telephone network and the IP data network. However, classical information theory is connection-based, limiting its utility even for IP, much less for a name-based architecture such as NDN. In a connection-based setting with a fixed number of source-destination pairs, the multi-dimensional generalization of classical point-to-point Shannon capacity is the network capacity region, consisting of all the source-destination communication rates achievable using any feasible coding scheme [20]. The corresponding coding problem is to find low-complexity error correcting codes which allow for reliable communication at the rates given by the capacity region. To realize the true potential of the NDN paradigm, we need a new fundamental theory of networked communication. This poses some key challenges.
In classical information theory, information streams sent over different source-destination pairs are usually assumed to be independent. In NDN, interest packets for a popular network application, and the data traffic generated in response, are likely to be highly statistically dependent, suggesting a natural role for multicast. For multicast with a single source, optimal network coding can minimize both the bandwidth and computational complexity required to send a fixed number of packets [42]. But NDN networks will typically have multiple data streams of interest to different sets of receivers. Thus, we need to develop optimal coding theory and practice for multiple-source multicast. The critical role of caching data in NDN also raises the importance of optimal asynchronous or delay-tolerant multicast. A theory for NDN must capture the essential tradeoff between wires and storage in optimizing communication performance, so that for a given set of link capacities and buffer sizes, we can analyze combinations of transmission and caching strategy to optimize network performance. Two additional issues not prominent in classical theory are the time value of information (information cached too long may be useless once reaching receivers) and the central role of mobility in assessing the tradeoff between storage and transmission [36].
2.8.2 Technical Approach
Since the NDN approach to networking is fundamentally different from traditional connection-oriented networking, our first task is to develop appropriate network performance measures within this new framework. Instead of considering source-destination transmission rates, we focus instead on measuring the total amount of information satisfied per unit time for the interest sources (nodes generating interest packets) within the network. As an initial estimate, this can be captured by the total consumed bit rate, i.e., the total bit rate arriving at nodes requesting content. To further discount for redundant content, we will use the more refined metric of total consumed entropy rate in bits per second, i.e., the total rate of statistically independent information arriving at nodes requesting content. This definition accounts for transmission of information over time and appropriately corrects for redundant content, but does not capture the impact of storage and mobility on transmission of information across space. To further account for the importance of spatial transmission, we will measure NDN capacity in bit-meters (one bit of information transported 1 meter toward a node requesting content) per second [37].
Once we have an appropriate performance metric, we will pose the following fundamental questions as in classical information theory: for a given set of link capacities, buffer sizes, interest and data generation rates, what are the achievable rate regions and complexity costs for feasible joint routing, scheduling, coding, and buffer management schemes? PARC’s CCN has provided one possible achievable scheme corresponding to a subset of the capacity region. Our long-term goal is to characterize the entire region. This involves developing successively more powerful routing, scheduling, coding, and buffer management algorithms which allow us to extend the frontier of the achievable region. Guided by the performance of these algorithms and combining with appropriate performance bounds, we will characterize the macroscopic scaling laws governing NDN network capacity, in a manner similar to [37]. This provides a useful starting point for studying the scalability of the NDN architecture. Next, we will incorporate issues beyond network capacity, such as latency and fairness. Not all points in the network capacity region are equally desirable, and we will investigate network management policies which achieve a given set of performance objectives in the optimal manner. These optimal policies are expected to differ significantly from those established in the classical network theory literature.
2.8.3 Progress for Theory Activities
We have made significant progress over the past year on developing the theoretical foundations of NDN by following the technical approach outlined above. We have focused on optimizing network performance according to the performance metric of total consumed bit rate described above. With this performance metric in mind, we have investigated the design of optimal dynamic forwarding and caching algorithms within the NDN framework.
The following specific setting is being investigated. Interest packets expressing interest in a particular type of data can enter the network at any node according to a given arrival process. These packets are routed toward nodes containing the data of interest. Once the Interest packets arrive at their destinations, Data packets containing the data of interest retrace backwards the route taken by the Interest packet which fetched it. Along the way, the Data packets are cached in appropriate nodes, in anticipation of future demand for the same data.
Assuming that a feasible routing algorithm has been designed so that topology discovery and data reachability are resolved, the problem is how to dynamically forward Interest packets toward nearest data sources, and how to cache the Data packets which are fetched in response to Interest packets, in anticipation of future interest in the same data. Since communication in space and in time should be investigated together in a larger context, the problem of forwarding and caching is investigated jointly. Sending data down a path is communication in space, and sending data from storage (via caching) is communication in time.
At present in NDN, no systematic forwarding or caching algorithms with optimality properties have been developed. In developing optimal forwarding/caching algorithms, several essential challenges must be addressed. First, under the network setting discussed here, we must decide on a reasonable performance metric under which optimal algorithms should be developed. Second, in developing optimal algorithms, we must reconcile the need to optimize network performance both at the current time and at a future time, in the presence of new demands. Third, the optimal algorithms must accommodate the demand-driven nature of the NDN traffic, in contrast with the nature of traditional communication-oriented traffic. We have made important progress in addressing each of these challenges.
With respect to the first challenge, consider a situation where interest packets for different data types arrive at network nodes according to stochastic arrival processes with given arrival rates. The task of the network is to satisfy these interest packets with data packets at the highest possible rate through forwarding and caching. Thus, as an initial step, we use the reasonable metric of total consumed bit rate to measure network performance. With respect to the second challenge, we have developed algorithms which are driven by dynamic measures of both the current and future demand for data packets in the network. These dynamic measures are used by the algorithm to determine dynamic forwarding and caching to maximize the rate of satisfied interest packets. With respect to the third challenge, we have developed algorithms which explicitly model bidirectional traffic (interest packets to data source, and data packets back to the interest source), and which explicitly model the collapsing and suppression of interest packets requesting the same data type (i.e. within a given time window, interest packets from different nodes requesting the same data type are collapsed into one interest packet and then forwarded; interest packets arriving to a node with a PIT entry for the requested data type are suppressed). Currently, a candidate algorithm which addresses all three challenges is being verified both theoretically and experimentally. The algorithm is expected to be thoroughly developed and tested in the next few months. In addition, we will provide theoretical justification on the optimality of this algorithm in the sense discussed above.
2.8.4 Publications
Our first publications summarizing results concerning optimal algorithms for forwarding and caching will be prepared within the next few months.
Section 3: Education
|
3.1 Objectives
Architectural thinking is a type of computational thinking that encompasses system principles, invariants, and design trade-offs. As networked computing systems such as the Internet grow rapidly in complexity along with our dependence on them, the ability to rigorously understand the fundamentals of network communication architectures becomes only more important.
The NDN architecture development gives us a unique opportunity to teach students how to think architecturally. We use the comparison between the IP architecture and the NDN architecture as specific case studies to show students architectural evolutions and to understand the big picture, as well as how individual components fit in. We use the actual NDN prototype development to help teach students how to assess the systemic impacts of design choices, training a future generation of engineers who can make design choices to strengthen a networked system rather than weaken it.
3.2 Approach
We are developing materials to teach architectural thinking integrated with NDN-enabled research:
- Comparative study of the IP and NDN architecture designs in classrooms;
- Development and evaluation of NDN applications as part of the NDN research effort; and
- Development of the NDN testbed together with the associated network operation, management, and monitoring designs and development.
Through our application developments, we also seek to serve and inspire interdisciplinary collaboration across scientific, medical, and educational research communities.
We use the NDN design as new curriculum material to encourage students to view networking in new ways. Today instructors strive to teach architectural concepts, but unfortunately students often focus on mechanics, e.g., what fields are in an IP header, rather than why those fields are in the IP header. We are starting the efforts to create an introductory lecture suitable for inclusion in standard undergraduate networking courses, which compares NDN to the traditional IP architecture, and encourages students to challenge established IP network models from architectural viewpoints. By presenting a real alternative, with a significant and growing deployed infrastructure base amenable to evaluation, we challenge students to think deeply about network design questions. As an example, a student cannot get by simply knowing what is in an IP header when faced with the question of “should we, and can we, deliver data without using addresses? ”
Students are also exposed to NDN architectural concepts in the context of real software development challenges, and use APIs to the core NDN layer to build software that explores these concepts. Implementing projects under both IP and NDN paradigms inform theoretical and practical discussion of networking concepts. Running the NDN variants on our testbeds lead to unexpected network behavior that challenges the testbed student operators.
Another way to teach architectural thinking is to examine the history, to compare different design choices at the time, to see what design decisions led to what kinds of consequences, both expected and unforeseen, and to revisit those decisions given what we have learned since. In addition to teaching architectural thinking from history and emerging NDN architecture, we record exchanges and discussions from the NDN design and development efforts, capturing the process of creating a new architecture to enable such research and teaching in the future.
3.3 Progress During the First Year
During the first year of the project we made a great start in integrating NDN research into education. Our achievements include running weekly NDN reading groups (Colorado State, UIUC, UCLA, Yale), adding introductory lectures in undergraduate courses (Arizona, Memphis), graduate seminar courses dedicated to NDN architecture research and development (Colorado State, UCLA), in addition to having both graduate and undergraduate students participating in the NDN research efforts. More specifically,
- Arizona
- Beichuan Zhang taught the course “CSc525: Computer Networks”, a graduate level computer networking class. After focusing on the current Internet for the bigger part of the semester, a few lectures were devoted to the basic NDN architecture and components, which broadened students view and encouraged them to think for the future Internet architecture. Beichuan Zhang also gave lectures on NDN in “CS496H: undergraduate research”, a seminar class for undergraduates to learn the faculty members research activities.
- Colorado State
- Dan Massey devoted several lectures to NDN in the first year graduate networking course CS557. The students were shown the NDN architecture along with IP architecture. Some student projects involved NDN caching and routing questions. Dan Massey also taught NDN in the graduate networking seminar course CS657. All the course projects were focused on the design and development of the NDN testbed monitoring and management.
- Memphis
- Lan Wang gave a lecture on NDN in an undergraduate networking course (COMP3825) in the context of improving Internet security. The students became very interested in NDN, and one of them has since joined the the NDN research project.
- UCLA
- Lixia Zhang taught graduate seminar course “CS217B: Advanced Topics in Internet Research” which has been devoted to NDN architecture for 2010 and 2011. The students conducted comparative studies not only between IP and NDN architecture but also between NDN and a set of other new architecture proposals. They also used PARC’s CCNx platform to develop a variety of applications.
- Yale
- Edmund Yeh held a reading group on information centric networking. The participants presented papers relevant to information-centric networking, and more broadly in the area of caching, routing, and mobility, to crystallize the crucial theoretical and algorithmic issues for the NDN project.
From our own experience in teaching architectural thinking, we developed a conjecture that it is not sufficient to teach students about a network architecture by simply presenting a descriptive paper that tells how the architecture works. It is the progression towards the final architecture design that is essential to convey. To this end we identified a series of five papers each for IP and NDN architecture designs to examine the progression along their developments, as described in the paper “Teaching Network Architecture through case Studies” to be presented at SIGCOMM 2011 Education Workshop.
We have developed an NDN project education page, http://named-data.net/education.html, to facilitate the exchange of reading lists, teaching material, and term project topics.
3.4 Publications
- “Teaching Network Architecture through Case Studies”, Dan Massey, Christos Papadopoulos, Lan Wang, Beichuan Zhang, Lixia Zhang.
SIGCOMM 2011 Education workshop, August 2011.
- NDN Project Education Webpage, http://named-data.net/education.html
Bibliography
- [1]
- Fast batch verification for modular exponentiation and digital signatures. In Advances in Cryptology – Eurocrypt 1998, pages 236-250, 1998.
[2]Martin Abadi. On SDSI’s Linked Local Name Spaces. Journal of Computer Security, 6(1-2):3-21, October 1998.
[3]Selim G. Akl and Peter D. Taylor. Cryptographic solution to a problem of access control in a hierarchy. ACM Trans. Comput. Syst., 1(3):239-248, 1983.
[4]Mikhail J. Atallah, Marina Blanton, Nelly Fazio, and Keith B. Frikken. Dynamic and efficient key management for access hierarchies. ACM Trans. Inf. Syst. Secur., 12(3):1-43, 2009.
[5]Giuseppe Ateniese, Jan Camenisch, Marc Joye, and Gene Tsudik. A practical and provably secure coalition-resistant group signature scheme. In CRYPTO, pages 255-270, 2000.
[6]Dirk Balfanz, Glenn Durfee, and D.K. Smetters. Making the impossible easy: Usable PKI. In Lorrie Faith Cranor and Simpson Garfinkel, editors, Security and Usability – Designing Secure Systems that People Can Use, chapter 16, pages 319-334. O’Reilly Media, Inc., 2005.
[7]Paul Baran. On distributed communications networks. IEEE Transactions on Communications Systems, 1964.
[8]Matt Blaze. A cryptographic file system for unix. In CCS ’93: Proceedings of the 1st ACM conference on Computer and communications security, pages 9-16, New York, NY, USA, 1993. ACM.
[9]M. Boguñá, D. Krioukov, and kc claffy. Navigability of complex networks. Nature Physics, 5:74-80, 2009.
[10]Dan Boneh, Xavier Boyen, and Hovav Shacham. Short group signatures. In CRYPTO, pages 41-55, 2004.
[11]Dan Boneh, Craig Gentry, Ben Lynn, and Hovav Shacham. Aggregate and verifiably encrypted signatures from bilinear maps. In Advances in Cryptology – Eurocrypt 2003, pages 416-432, 2003.
[12]Dan Boneh, Craig Gentry, and Brent Waters. Collusion resistant broadcast encryption with short ciphertexts and private keys. In CRYPTO ’05: Proceedings of the 25th Annual International Cryptology Conference on Advances in Cryptology, pages 258-275. Springer-Verlag, 2005.
[13]Dan Boneh, Benjamin Lynn, and H. Shacham. Short signatures from the weil pairing. In ASIACRYPT01: Advances in Cryptology – ASIACRYPT: International Conference on the Theory and Application of Cryptology. LNCS, Springer-Verlag, 2001.
[14]et al. C. Wiseman. A remotely accessible network processor-based router for network experimentation. 2008.
[15]Jan Camenisch and Anna Lysyanskaya. Dynamic accumulators and application to efficient revocation of anonymous credentials. In CRYPTO, pages 61-76, 2002.
[16]A. Chaintreau, P. Fraigniaud, and E. Lebhar. Opportunistic spatial gossip over mobile social networks. In WOSN, 2008.
[17]David Chaum and E. van Heijst. Group signatures. In EUROCRYPT, pages 257-265. Springer-Verlag, 1991. LNCS 547.
[18]M Collins, D Schweitzer, and D Massey. Canvas: a regional assessment exercise for teaching security concepts. Proceedings from the 12th Colloquium for Information Systems Security Education, 2008.
[19]D. Cooper, S. Santesson, S. Farrell, S. Boeyen, R. Housley, and W. Polk. Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile. IETF, May 2008. RFC 5280.
[20]T. M. Cover and J. A. Thomas. Elements of Information Theory. Wiley-Interscience, New York, 1991.
[21]E. M. Daly and M. Haahr. Social network analysis for routing in disconnected delay-tolerant MANETs. In MobiHoc, 2007.
[22]S. Dharmapurikar, P. Krishnamurthy, and D. E. Taylor. Longest prefix matching using bloom filters. 2003.
[23]Xuhua Ding, Daniele Mazzocchi, and Gene Tsudik. Equipping smart devices with public key signatures. ACM Trans. Internet Techn., 7(1), 2007.
[24]Xuhua Ding and Gene Tsudik. Simple identity-based cryptography with mediated rsa. In CT-RSA, pages 193-210, 2003.
[25]Xuhua Ding, Gene Tsudik, and Shouhuai Xu. Leak-free group signatures with immediate revocation. In IEEE ICDCS, pages 608-615, 2004.
[26]Roger Dingledine, Nick Mathewson, and Paul Syverson. Tor: The second-generation onion router. In Proceedings of the 13th USENIX Security Symposium, August 2004.
[27]Roger Dingledine, Nick Mathewson, and Paul Syverson. Tor: The second-generation onion router. In USENIX, 2004.
[28]Carl M. Ellison, Bill Frantz, Butler Lampson, Ron Rivest, Brian M. Thomas, and Tatu Ylonen. SPKI Certificate Theory, September 1999. RFC2693.
[29]Amos Fiat and Moni Naor. Broadcast encryption. In CRYPTO ’93: Proceedings of the 13th annual international cryptology conference on Advances in cryptology, pages 480-491, New York, NY, USA, 1994. Springer-Verlag New York, Inc.
[30]Girija Narlikar Francis Zane and Anindya Basu. Coolcams: Power-efficient tcams for forwarding engines. 2003.
[31]L Gao. On Inferring Autonomous System Relationships in the Internet. IEEE/ACM TRANSACTIONS ON NETWORKING, 9(6), dec 2001.
[32]The GENI initiative. http://www.geni.net/.
[33]T. R. G. Green. Instructions and descriptions: some cognitive aspects of programming and similar activities. In V. Di Gesù, S. Levialdi, and L. Tarantino, editors,Proceedings of Working Conference on Advanced Visual Interfaces (AVI 2000), pages 21-28. ACM Press, 2000.
[34]TG Griffin, FB Shepherd, and G Wilfong. The stable paths problem and interdomain routing. IEEE/ACM Transactions on Networking (TON), 10(2):232-243, 2002.
[35]M. Gromov. Metric Structures for Riemannian and Non-Riemannian Spaces. Birkhäuser, Boston, 2007.
[36]M. Grossglauser and D. N. C. Tse. Mobility increases the capacity of ad hoc wireless networks. IEEE Trans. on Networking, 10:47-86, Aug. 2002.
[37]P. Gupta and P. R. Kumar. The capacity of wireless networks. IEEE Trans. on Information Theory, 46(2):388-404, Mar. 2000.
[38]Peter Gutmann. Underappreciated security mechanisms. http://www.cs.auckland.ac.nz/\~pgut001/pubs/underappreciated.pdf.
[39]Peter Gutmann. Pki: It’s not dead, just resting. IEEE Computer, 35(8):41-49, 2002.
[40]Peter Gutmann. Plug-and-play PKI: A PKI your mother can use. In Proceedings of the 12th USENIX Security Symposium, pages 45-58, Washington, D.C., August 2003.
[41]L. Harn. Batch verifying multiple DSA-type digital signatures. Electronics Letters, 34:870-871, 1998.
[42]T. Ho, R. Koetter, M. Médard, M. Effros, J. Shi, and D. Karger. A random linear network coding approach to multicast. IEEE Trans. on Information Theory, 52(10):4413-4430, Oct. 2006.
[43]P. Hui, J. Crowcroft, and E. Yoneki. BUBBLE rap: Social-based forwarding in delay tolerant networks. In MobiHoc, 2008.
[44]G Huston. Interconnection, peering, and settlements. Proc. INET, 1999.
[45]V Jacobson, DK Smetters, JD Thornton, MF Plass, NH Briggs, and RL Braynard. Networking named content. Proceedings of the 5th international conference on Emerging networking experiments and technologies, pages 1-12, 2009.
[46]Van Jacobson, Diana K. Smetters, Nicholas H. Briggs, Michael F. Plass, Paul Stewart James D. Thornton, and Rebecca L. Braynard. Voccn: Voice-over content centric networks. pages 1-6, 2009.
[47]Dan Jen, Michael Meisel, He Yan, Daniel Massey, Lan Wang, Beichuan Zhang, and Lixia Zhang. Towards A Future Internet Architecture: Arguments for Separating Edges from Transit Core. In ACM Workshop on Hot Topics in Networks, 2008.
[48]P. DeHart J. Freestone A. Heller B. Kuhns F. Kumar S. Lockwood J. Lu J. Wilson M. Wiseman C. J.S. Turner, Crowley and D. Zar. Supercharging planetlab: A high performance, multi-application, overlay network platform. 2007.
[49]Mike Just, Evangelos Kranakis, Danny Krizanc, and Paul van Oorschot. On key distribution via true broadcasting. In CCS ’94: Proceedings of the 2nd ACM Conference on Computer and communications security, pages 81-88, New York, NY, USA, 1994. ACM.
[50]D. Krioukov, F. Papadopoulos, M. Boguñá, and A. Vahdat. Greedy forwarding in scale-free networks embedded in hyperbolic metric spaces. ACM SIGMETRICS Perf E R, 37(2):15-17, 2009.
[51]D. Krioukov, F. Papadopoulos, A. Vahdat, and M. Boguñá. Curvature and temperature of complex networks. Phys Rev E, 80:035101(R), 2009.
[52]S. Kumar and P. Crowley. Segmented hash: An efficient hash table implementation for high-performance networking subsystems. 2005.
[53]J. Turner M. Waldvogel, G. Varghese and B. Plattner. Scalable high speed ip routing lookups. 1997.
[54]Dan Massey, Lan Wang, Beichuan Zhang, and Lixia Zhang. A Scalable Routing System Design for Future Internet. In Proc. of ACM SIGCOMM Workshop on IPv6, 2007.
[55]A. J. McAuley and P. Francis. Fast routing table lookup using cams. 1993.
[56]Ralph Charles Merkle. Secrecy, authentication, and public key systems. PhD thesis, 1979.
[57]A. Miklas, K. Gollu, K. Chan, S. Saroiu, K. Gummadi, and E. de Lara. Exploiting social interactions in mobile systems. In UbiComp, 2007.
[58]A. Mtibaa, A. Chaintreau, J. LeBrun, E. Oliver, A.-K. Pietilainen, and C. Diot. Are you moved by your social network application? In WOSN, 2008.
[59]A. Mtibaa, M. May, M. Ammar, and C. Diot. PeopleRank: combining social and contact information for opportunistic forwarding. In INFOCOM, 2010.
[60]M. Myers, R. Ankney, A. Malpani, S. Galperin, and C. Adams. X.509 Internet Public Key Infrastructure Online Certificate Status Protocol – OCSP. RFC 2560 (Proposed Standard), June 1999.
[61]Einar Mykletun, Maithili Narasimha, and Gene Tsudik. Authentication and integrity in outsourced databases. In NDSS, 2004.
[62]Dalit Naor, Moni Naor, and Jeffrey B. Lotspiech. Revocation and tracing schemes for stateless receivers. In CRYPTO ’01: Proceedings of the 21st Annual International Cryptology Conference on Advances in Cryptology, pages 41-62, London, UK, 2001. Springer-Verlag.
[63]T. Okamoto and J. Stern. Almost Uniform Density of Power Residues and the Provable Security of ESIGN. In ASIACRYPT, 2003.
[64]Open network lab. http://onl.wustl.edu.
[65]Eric Osterweil, Dan Massey, Batsukh Tsendjav, Beichuan Zhang, and Lixia Zhang. Security Through Publicity. In HOTSEC ’06, 2006.
[66]Lasse Overlier and Paul Syverson. Locating hidden servers. IEEE Symposium on Security and Privacy, 100-114, 2006.
[67]F. Papadopoulos, D. Krioukov, M. Boguñá, and A. Vahdat. Greedy forwarding in dynamic scale-free networks embedded in hyperbolic metric spaces. InINFOCOM, 2010.
[68]Vasileios Pappas, Zhiguo Xu, Songwu Lu, Daniel Massey, Andreas Terzis, and Lixia Zhang. Impact of configuration errors on dns robustness. In SIGCOMM, pages 319-330, 2004.
[69]Jarno Rajahalme, Mikko Särelä, Pekka Nikander, and Sa su Tarkoma. Incentive-compatible caching and peering in data-oriented networks. ReArch ’08 – Re-Architecting the Internet, 2008.
[70]Ronald L. Rivest and Butler Lampson. SDSI – A Simple Distributed Security Infrastructure. Technical report, MIT, 1996.
[71]Scalable Networks. QualNet simulator. http://www.scalable-networks.com/products/qualnet/.
[72]C.E. Shannon. A mathematical theory of communication. Bell System Technical Journal, 27:379-423, 623-656, July, October 1948.
[73]The Route Views Project. http://www.routeviews.org/.
[74]Gene Tsudik and Shouhuai Xu. Accumulating composites and improved group signing. In ASIACRYPT, pages 269-286, 2003.
[75]Jonathan S. Turner, Patrick Crowley, John DeHart, Amy Freestone, Brandon Heller, Fred Kuhns, Sailesh Kumar, John Lockwood, Jing Lu, Michael Wilson, Charles Wiseman, and David Zar. Supercharging planetlab: a high performance, multi-application, overlay network platform. SIGCOMM Comput. Commun. Rev., 37(4):85-96, 2007.
[76]Van Jacobson. Circuits: the search for a cure. http://www.sigcomm.org/sites/default/files/award-talks/vj-sigcomm01.pdf, 2001.
[77]Dan Wendlandt, David Andersen, and Adrian Perrig. Perspectives: Improving SSH-style host authentication with multi-path probing. In Proc. USENIX Annual Technical Conference, Boston, MA, June 2008.
[78]Alma Whitten and J. D. Tygar. Why Johnny can’t encrypt: A usability evaluation of PGP 5.0. In Proceedings of the 8th USENIX Security Symposium, pages 169-183, Washington, DC, August 1999.
[79]X. Zhao, Y. Liu, L. Wang, and B. Zhang. On the Aggregatability of Router Forwarding Tables. In Proc. IEEE INFOCOM, 2010.
[80]Philip R. Zimmermann. The Official PGP User’s Guide. MIT Press, Cambridge, MA, USA, 1995. ISBN 0-262-74017-6.
Footnotes:
1We define routing plane as the collection of all the running routing protocols together with the forwarding state they establish. In the rest of the writing we use routingand routing plane in an interchangeable way.
2In NDN an interface is called face because packets are not only forwarded over hardware network interfaces but also exchanged directly with application processes.
3In fact, condensed and batch schemes are very similar, except that, in the former, individual message signatures are available to the verifier. Whereas, in the latter, they are folded into a single condensed signature and that is the only signature the verifier sees.
4Note the PIT helps protect against loops in the multi-path selection.
File translated from TEX by TTH, version 4.01.
On 24 Feb 2012, 12:42.